
In today’s digital world, our lives and businesses run on a vast, intricate web of interconnected systems. Think about it: from your morning coffee order to global financial transactions, everything relies on distributed systems working seamlessly. But here’s a truth often whispered in server rooms: these complex systems, by their very nature, are destined to encounter glitches. Failures aren’t just possibilities; they’re an inevitable part of the landscape, like that one sock that always disappears in the laundry. 😀

We’re talking about everything from a single server deciding to take an unexpected nap (a “node crash”) to entire communication lines going silent, splitting your system into isolated islands (a “network partition”). Sometimes, messages just vanish into the ether, or different parts of your system end up with conflicting information, leading to messy “data inconsistencies”.
It’s like everyone in the office has a different version of the same meeting notes, and nobody knows which is right. Even seemingly minor issues, like a service briefly winking out, can trigger a domino effect, turning a small hiccup into a full-blown “retry storm” as clients desperately try to reconnect, overwhelming the very system they’re trying to reach. Imagine everyone hitting refresh on a website at the exact same time because it briefly went down. Isn’t this the digital equivalent of a stampede.
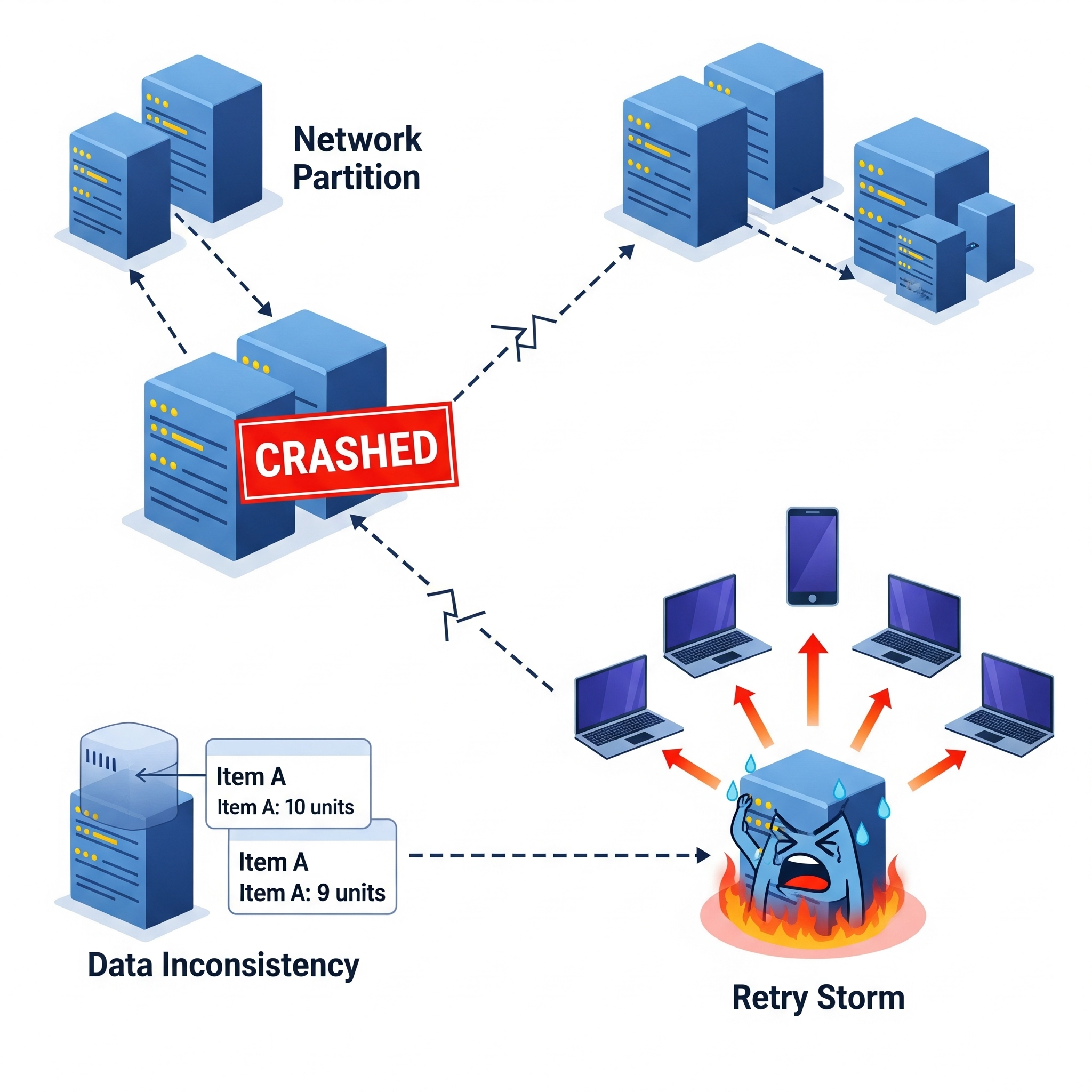
This isn’t just about fixing things when they break. It’s about building systems that can pick themselves up, dust themselves off, and keep running, often without anyone even noticing. This, dear readers, is the silent heroism of automated system recovery.
The Clock and the Data: Why Every Second (and Byte) Counts
At the heart of any recovery strategy are two critical metrics, often abbreviated because, well, we love our acronyms in tech:
- Recovery Time Objective (RTO): This is your deadline. It’s the absolute maximum time your application can afford to be offline after a disruption. Think of it like a popular online retailer during the sale on Big Billion days or the Great Indian Festival. If their website goes down for even a few minutes, that’s millions in lost sales and a lot of very unhappy shoppers. Their RTO would be measured in seconds, maybe a minute. For a less critical internal tool, like a quarterly report generator, an RTO of a few hours might be perfectly fine.
- Recovery Point Objective (RPO): This defines how much data you’re willing to lose. It’s usually measured in a time interval, like “the last five minutes of data”. For that same retailer, losing even a single customer’s order is a no-go. Their RPO would be zero. But for this blog, if the last five minutes of comments disappear, it’s annoying, but not catastrophic. My RPO could be a few hours and for some news blogs few minutes would be acceptable.
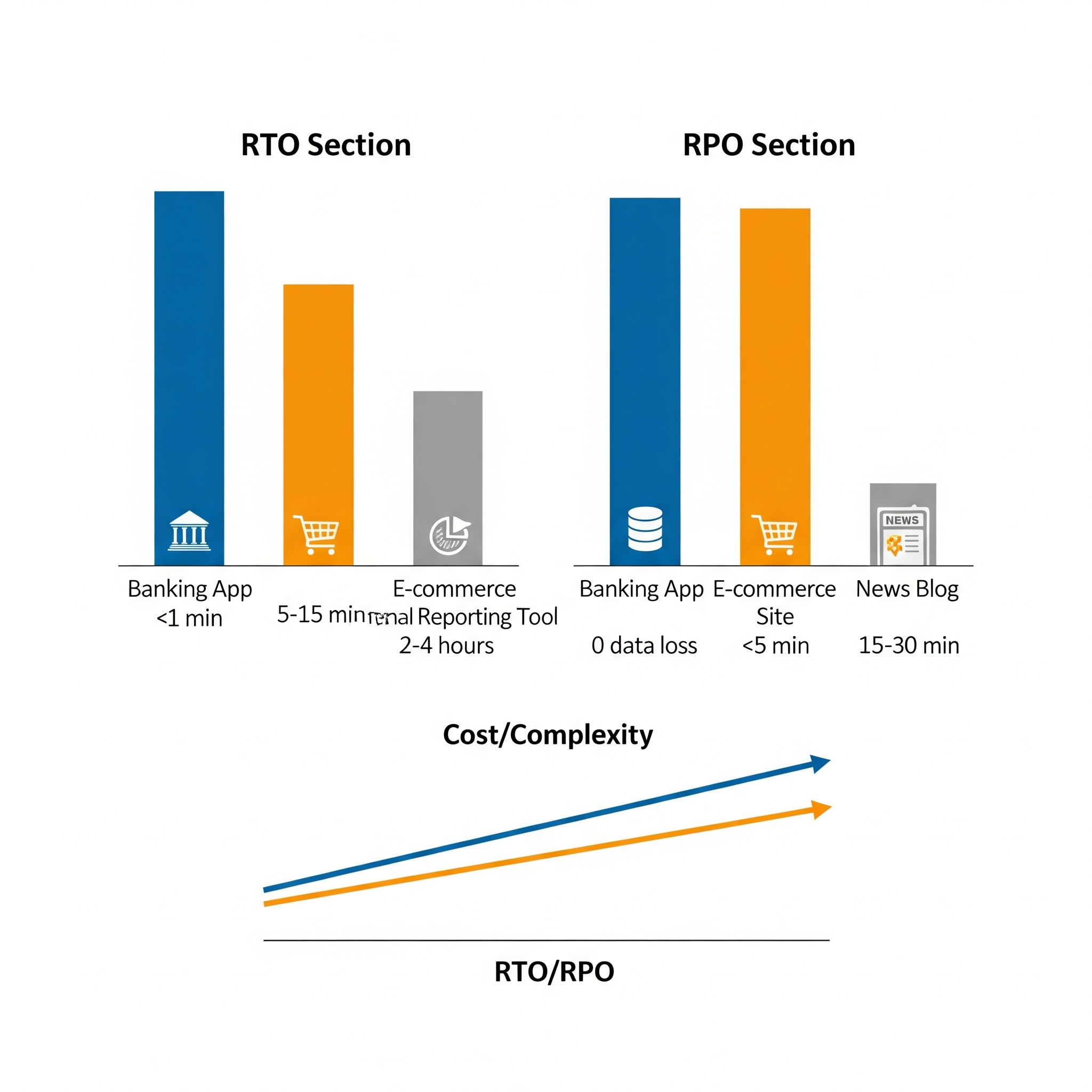
These aren’t just technical jargon; they’re business decisions. The tighter your RTO and RPO, the more complex and, frankly, expensive your recovery solution will be. It’s like choosing between a spare tire you have to put on yourself (longer RTO, lower cost) and run-flat tires that keep you going (near-zero RTO, higher cost). You pick your battles based on what your business can actually afford to lose, both in time and data.
Building on Solid Ground: The Principles of Resilience
So, how do we build systems that can withstand the storm? It starts with a few foundational principles:
1. Fault Tolerance, Redundancy, and Decentralization
Imagine a bridge designed so that if one support beam fails, the entire structure doesn’t collapse. That’s fault tolerance. We achieve this through redundancy, which means duplicating critical components – servers, network paths, data storage – so there’s always a backup ready to jump in. Think of a data center with two power lines coming in from different grids. If one goes out, the other kicks in. Or having multiple copies of your customer database spread across different servers.
Decentralisation ensures that control isn’t concentrated in one place. If one part goes down, the rest of the system keeps chugging along, independently but cooperatively. It’s like a well-trained team where everyone knows how to do a bit of everything, so if one person calls in sick, the whole project doesn’t grind to a halt.
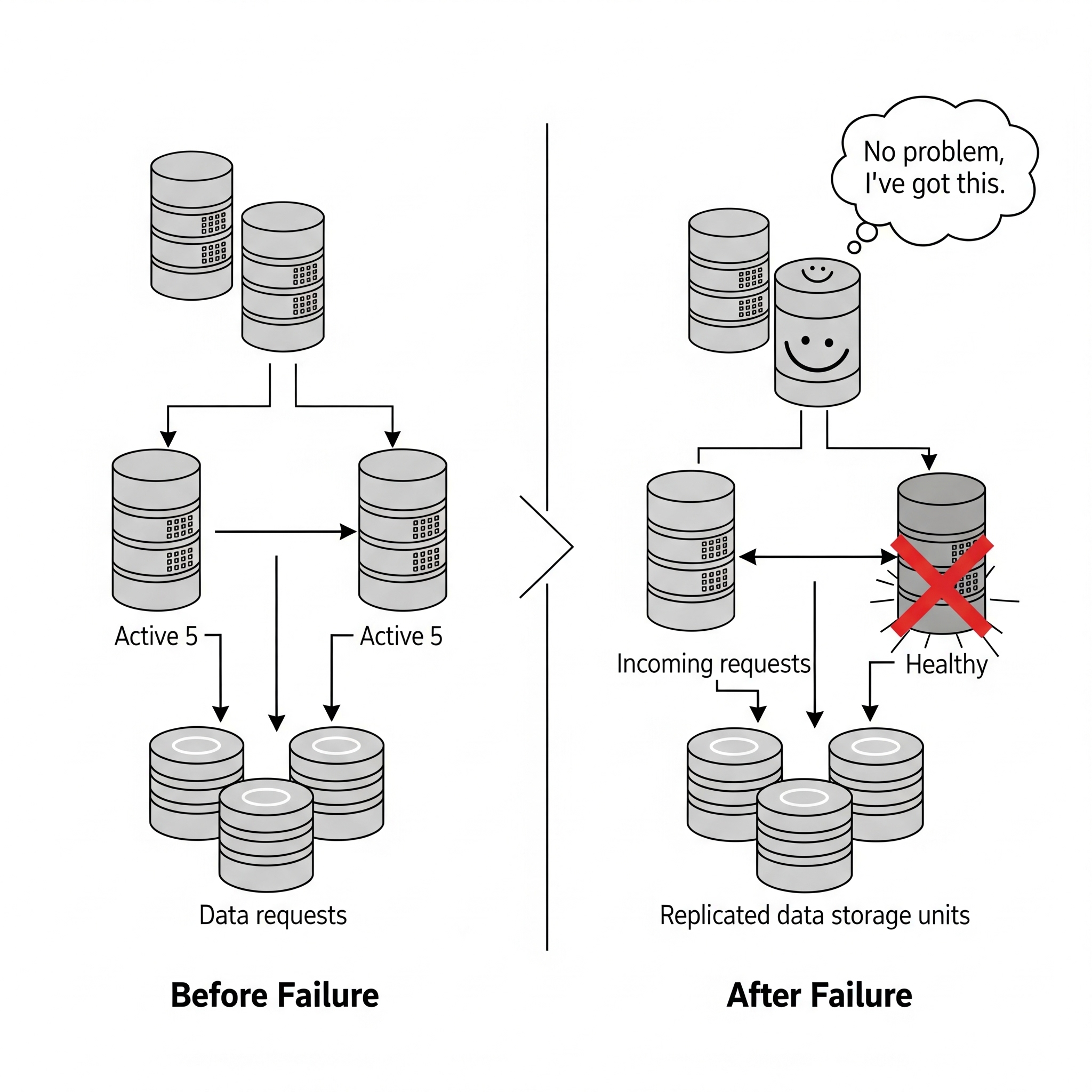
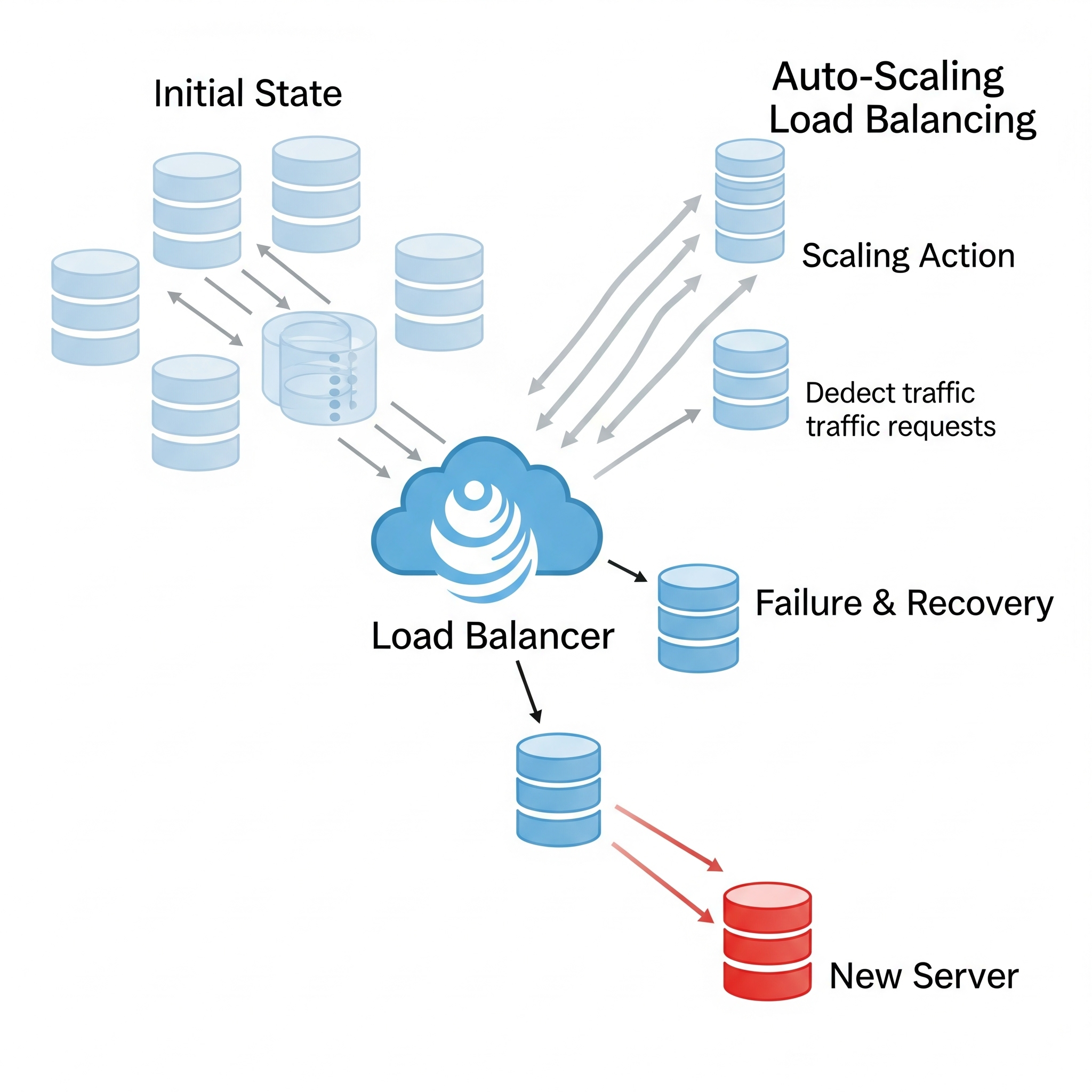
2. Scalability and Performance Optimization
A resilient system isn’t just tough; it’s also agile. Scalability means it can handle growing demands, whether by adding more instances (horizontal scaling) or upgrading existing ones (vertical scaling). Think of a popular streaming service. When a new hit show drops, they don’t just hope their servers can handle the millions of new viewers. They automatically spin up more servers (horizontal scaling) to meet the demand. If one server crashes, they just spin up another, no fuss.
Performance optimization, meanwhile, ensures your system runs efficiently, distributing requests evenly to prevent any single server from getting overwhelmed. It’s like a traffic controller directing cars to different lanes on a highway to prevent a massive jam.
3. Consistency Models
In a distributed world, keeping everyone on the same page about data is a monumental task. Consistency ensures all parts of your system have the same information and act the same way, even if lots of things are happening at once. This is where consistency models come in.
- Strong Consistency means every read gets the absolute latest data, no matter what. Imagine your bank account. When you check your balance, you expect to see the exact current amount, not what it was five minutes ago. That’s strong consistency – crucial for financial transactions or inventory systems where every single item counts.
- Eventual Consistency is more relaxed. It means data will eventually be consistent across all replicas, but there might be a brief period where some parts of the system see slightly older data. Think of a social media feed. If you post a photo, it might take a few seconds for all your followers to see it on their feeds. A slight delay is fine; the world won’t end. This model prioritises keeping the service available and fast, even if it means a tiny bit of lag in data synchronisation.
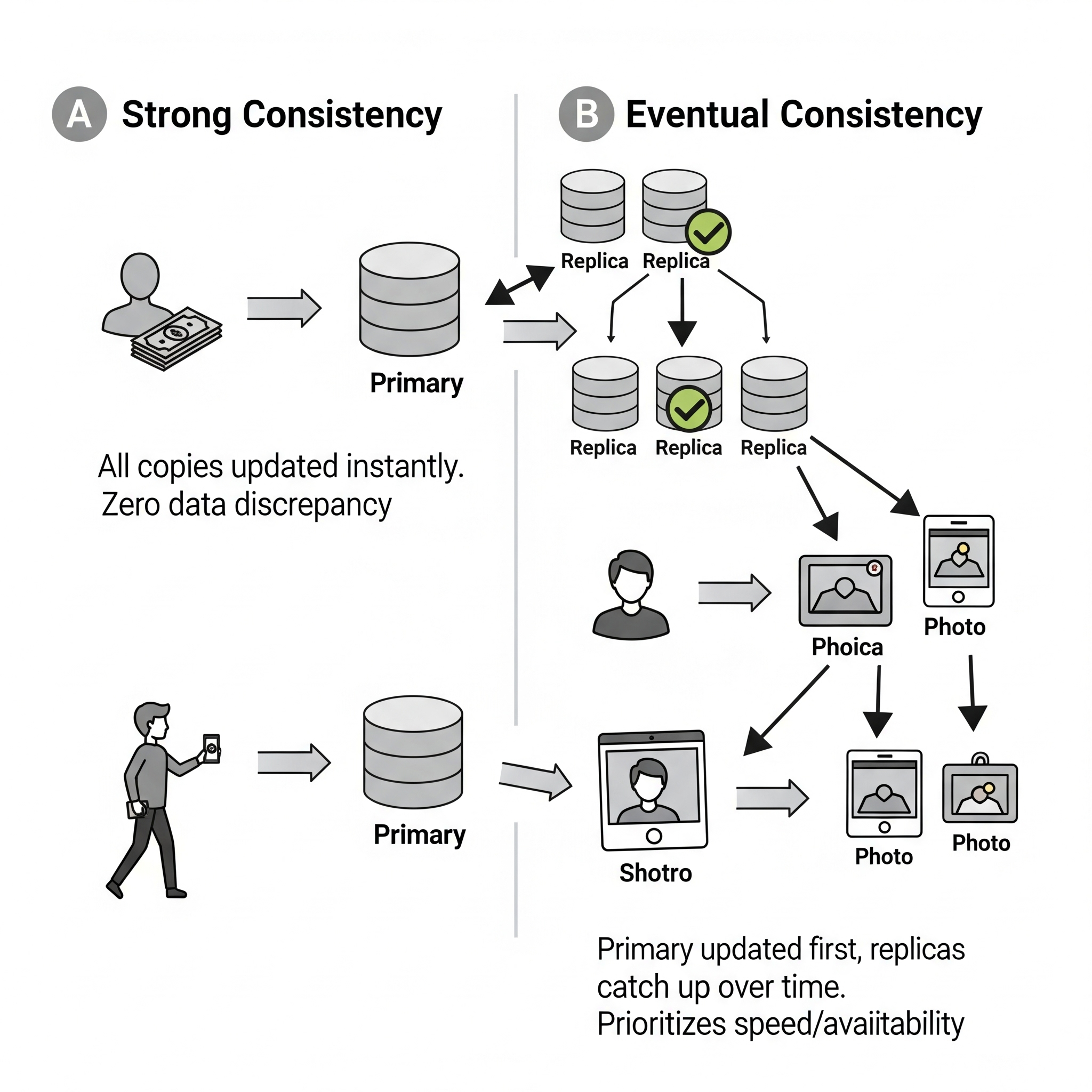
The choice of consistency model is a fundamental trade-off, often summarised by the CAP theorem (Consistency, Availability, Partition Tolerance) – you can’t perfectly have all three. It’s like trying to be perfectly on time, perfectly available, and perfectly consistent all at once – sometimes you have to pick your battles. Your decision here directly impacts how complex and fast your recovery will be, especially for applications that hold onto data.
In my next post, I will dive into the world of stateless applications and discover why their “forgetful” nature makes them champions of rapid, automated recovery. Stay tuned!
References and Recommended Reads
Here is an exhaustive set of references I have used for the series:
- “Achieving High Availability and Fault Tolerance in Cloud-Based Systems.” ResearchGate, ResearchGate, 6 Feb. 2025, www.researchgate.net/publication/388654435_ACHIEVING_HIGH_AVAILABILITY_AND_FAULT_TOLERANCE_IN_CLOUD-BASED_SYSTEMS. Accessed 9 July 2025.
- “Automated System Disaster Recovery Best Practices.” , Number Analytics, 18 June 2025, www.numberanalytics.com/blog/automation-system-disaster-recovery-best-practices. Accessed 9 July 2025.
- “Disaster Recovery Planning in Cloud-Native Architectures.” ResearchGate, ResearchGate, 3 Apr. 2025, www.researchgate.net/publication/390399202_Disaster_Recovery_Planning_in_Cloud-_Native_Architectures. Accessed 9 July 2025.
- “Disaster Recovery Scenarios Planning Guide.”, Google, 5 July 2024, cloud.google.com/architecture/dr-scenarios-planning-guide. Accessed 9 July 2025.
- “Disaster Recovery Using Amazon Aurora.” AWS Solutions Library, Amazon Web Services, Aug. 2023, aws-solutions-library-samples.github.io/ai-ml/disaster-recovery-using-amazon-aurora.html. Accessed 9 July 2025.
- “Failover Mechanisms in System Design.” GeeksforGeeks, www.geeksforgeeks.org/system-design/failover-mechanisms-in-system-design/. Accessed 9 July 2025.
- “High Availability Architecture.” Meridian IT Inc., 3 Feb. 2025, www.meridianitinc.com/blog/high-availability-architecture. Accessed 9 July 2025.
- “How to Build Resilient Distributed Systems.” Axelerant, www.axelerant.com/blog/how-to-build-resilient-distributed-systems. Accessed 9 July 2025.
- “Plan Disaster Recovery.” Microsoft Learn, Microsoft, 14 May 2025, learn.microsoft.com/en-us/power-platform/guidance/adoption/plan-disaster-recovery. Accessed 9 July 2025.
- “Stateless and Stateful Systems in System Design.”, GeeksforGeeks, www.geeksforgeeks.org/system-design/stateless-and-stateful-systems-in-system-design/. Accessed 9 July 2025.
- “Stateful vs Stateless Applications: A Comprehensive Comparison.”, AutoMQ, 14 May 2025, www.automq.com/blog/stateless-vs-stateful-architecture-a-comprehensive-comparison. Accessed 9 July 2025.
- “Stateful vs Stateless Applications.” Red Hat, Red Hat, www.redhat.com/en/topics/cloud-native-apps/stateful-vs-stateless. Accessed 9 July 2025.
- “Stateless vs. Stateful AWS Applications.”, Digital Cloud Training, www.digitalcloud.training/stateful-vs-stateless-aws-applications/. Accessed 9 July 2025.
- “Synchronous Replication vs. Asynchronous Replication.” Pure Storage Blog, Pure Storage, 2 June 2022, blog.purestorage.com/purely-educational/synchronous-replication-vs-aynchronous-replication/. Accessed 9 July 2025.
- “The Challenges of Failures in Distributed Systems: Patterns and Anti-Patterns.“, Statsig, www.statsig.com/perspectives/handling-failures-in-distributed-systems-patterns-and-anti-patterns. Accessed 9 July 2025.
- “Various Failures in Distributed System.”, GeeksforGeeks, www.geeksforgeeks.org/computer-networks/various-failures-in-distributed-system/. Accessed 9 July 2025. Sources and related content

