
Remember our last chat about automated system recovery? We talked about the inevitable chaos of distributed systems and how crucial it is to design for failure. We also touched on RTOs and RPOs – those critical deadlines for getting back online and minimizing data loss. Today, we’re going to meet the first type of application in our recovery framework: the stateless application. And trust me, their “forgetful” nature is actually their greatest superpower when it comes to bouncing back from trouble.

Meet the Forgetful Ones: What Exactly is a Stateless App?
Imagine you walk up to a vending machine. You put in your money, press a button, and out pops your snack. The machine doesn’t remember you from yesterday, or even from five minutes ago when you bought a drink. Each interaction is a fresh start, a clean slate. That, my friends, is a stateless application in a nutshell.
A stateless system is designed so it doesn’t hold onto any client session information on the server side between requests. Every single request is treated as if it’s the very first one, carrying all the necessary information within itself.
Think of it like this:
- A vending machine: You put money in, get a snack. The machine doesn’t care if you’re a regular or a first-timer.
- A search engine: You type a query, get results. The server doesn’t remember your last search unless you explicitly tell it to.
- A public library’s book lookup: You search for a book, get its location. The system doesn’t remember what other books you’ve looked up or if you’ve checked out books before.
Why is this “forgetfulness” a good thing?
- Independence: Each request is a self-contained unit. No baggage from previous interactions.
- Scalability: This is huge! Because no session data is tied to a specific server, you can easily spread requests across tons of servers. Need more power? Just add more machines, and your load balancer will happily send traffic their way. This is called horizontal scaling, and it’s effortless.
- Resilience & Fault Tolerance: If a server handling your request suddenly decides to take a coffee break (i.e., crashes), no biggie! No user session data is lost because it wasn’t stored there in the first place. The next request just gets routed to a different, healthy server.
- Simplicity: Less state to manage means less complex code, making these apps easier to design, build, and maintain.
- Lower Resource Use: They don’t need to hog memory or processing power to remember past interactions.
Common examples you interact with daily include web servers (like the one serving this blog post!), REST APIs, Content Delivery Networks (CDNs), and DNS servers.
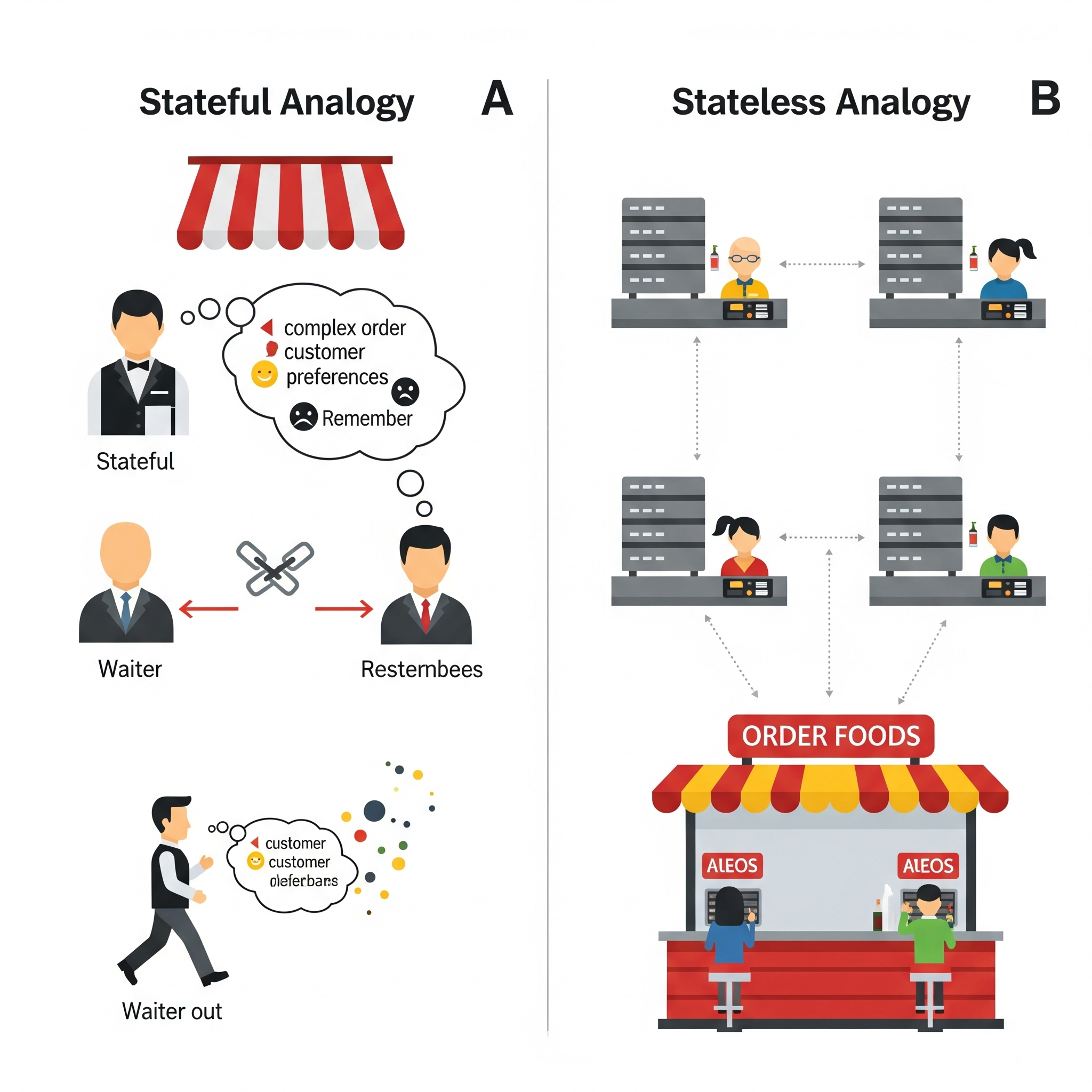
The above comparision clearly illustrate the core difference between stateful and stateless applications using a simple, relatable analogy, emphasizing the “forgetful” nature of statelessness.
Why Their Forgetfulness is a Superpower for Recovery
Here’s where the magic happens for automated recovery. Because stateless applications don’t store any unique, session-specific data on the server itself, if an instance fails, you don’t have to worry about recovering its “memory.” There’s nothing to recover!
This allows for a “disposable instance” paradigm:
- Faster Recovery Times: Automated recovery for stateless apps can be incredibly quick, often in seconds. There’s no complex data replication or synchronization needed for individual instances to get back up to speed. Highly optimized systems can even achieve near-instantaneous recovery.
- Simplified Failover: If a server goes down, new instances can be spun up rapidly on different machines. Incoming requests are immediately accepted by these new instances without waiting for any state synchronization. It’s like having an endless supply of identical vending machines – if one breaks, you just wheel in another.
This approach aligns perfectly with modern cloud-native principles: treat your infrastructure components as disposable and rebuildable.
The Dynamic Trio: Load Balancing, Auto-Scaling, and Automated Failover
The rapid recovery capabilities of stateless applications are primarily driven by three best friends working in perfect harmony:
- Load Balancing: This is your digital traffic cop. It efficiently distributes incoming requests across all your healthy servers, making sure no single server gets overwhelmed. This is crucial for keeping things running smoothly and for spreading the load when you add more machines.
- Auto-Scaling: This is your automatic capacity manager. It dynamically adds or removes server instances based on real-time performance metrics. If traffic spikes, it spins up more servers. If a server fails, it automatically provisions a new one to replace it, ensuring you always have enough capacity.
- Automated Failover: This is the seamless transition artist. When a component fails, automated failover instantly reroutes operations to a standby or redundant component, minimizing downtime without anyone lifting a finger. For stateless apps, this is super simple because there’s no complex session data to worry about.
Illustration: How the Dynamic Trio Work Together
Imagine your website is running on a few servers behind a load balancer. If one server crashes, the load balancer immediately notices it’s unhealthy and stops sending new requests its way. Simultaneously, your auto-scaling service detects the lost capacity and automatically launches a brand new server. Once the new server is ready, the load balancer starts sending traffic to it, and your users never even knew there was a hiccup.
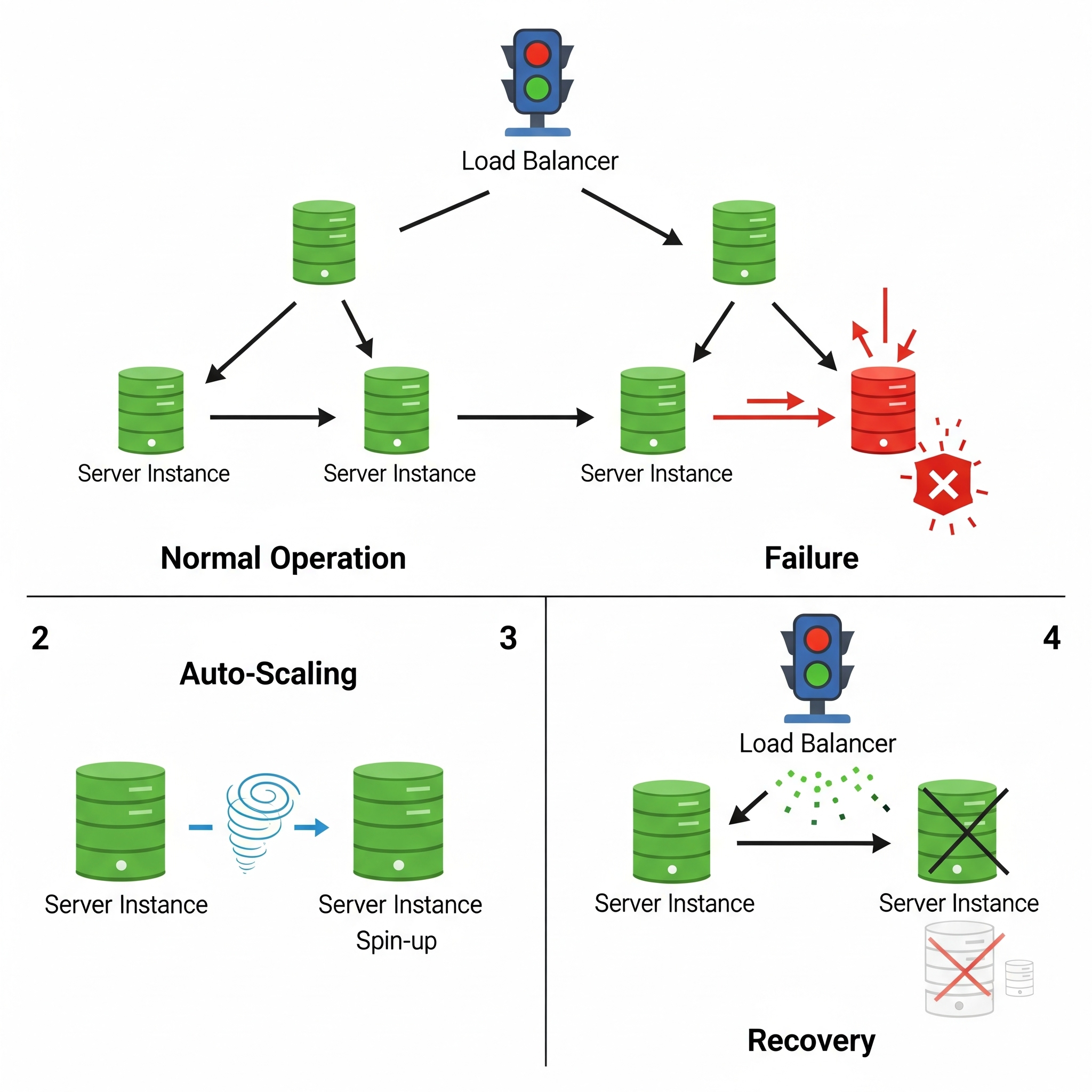
It’s a beautiful, self-healing dance.
Cloud-Native: The Natural Habitat for Stateless Heroes
It’s no surprise that stateless applications thrive in cloud-native environments. Architectures like micro-services, containers, and serverless computing are practically built for them.
- Microservices Architecture: Breaking your big application into smaller, independent services means if one tiny service fails, it doesn’t take down the whole house. Each microservice can be stateless, making it easier to isolate faults and scale independently.
- Serverless Computing: Think AWS Lambda or Azure Functions. You just write your code, and the cloud provider handles all the infrastructure. These functions are designed to respond to individual events without remembering past actions, making them perfect for stateless workloads. They can start almost instantaneously!
- Containerization (e.g., Kubernetes): Containers package your app and all its bits into a neat, portable unit. While Kubernetes has evolved to handle stateful apps, it’s a superstar for managing and recovering stateless containers, allowing for super-fast deployment and scaling.
- Managed Services: Cloud providers offer services that inherently provide high availability and automated scaling. For stateless apps, this means less operational headache for you, as the cloud provider handles the underlying resilience.
The bottom line? If you’re building a new stateless application, going cloud-native should be your default. It’s the most efficient way to achieve robust, automated recovery, letting you focus on your code, not on babysitting servers.
In our next post, we’ll tackle the trickier side of the coin: stateful applications. These guys do remember things, and that memory makes their recovery a whole different ballgame. Stay tuned!
Leave a Reply