
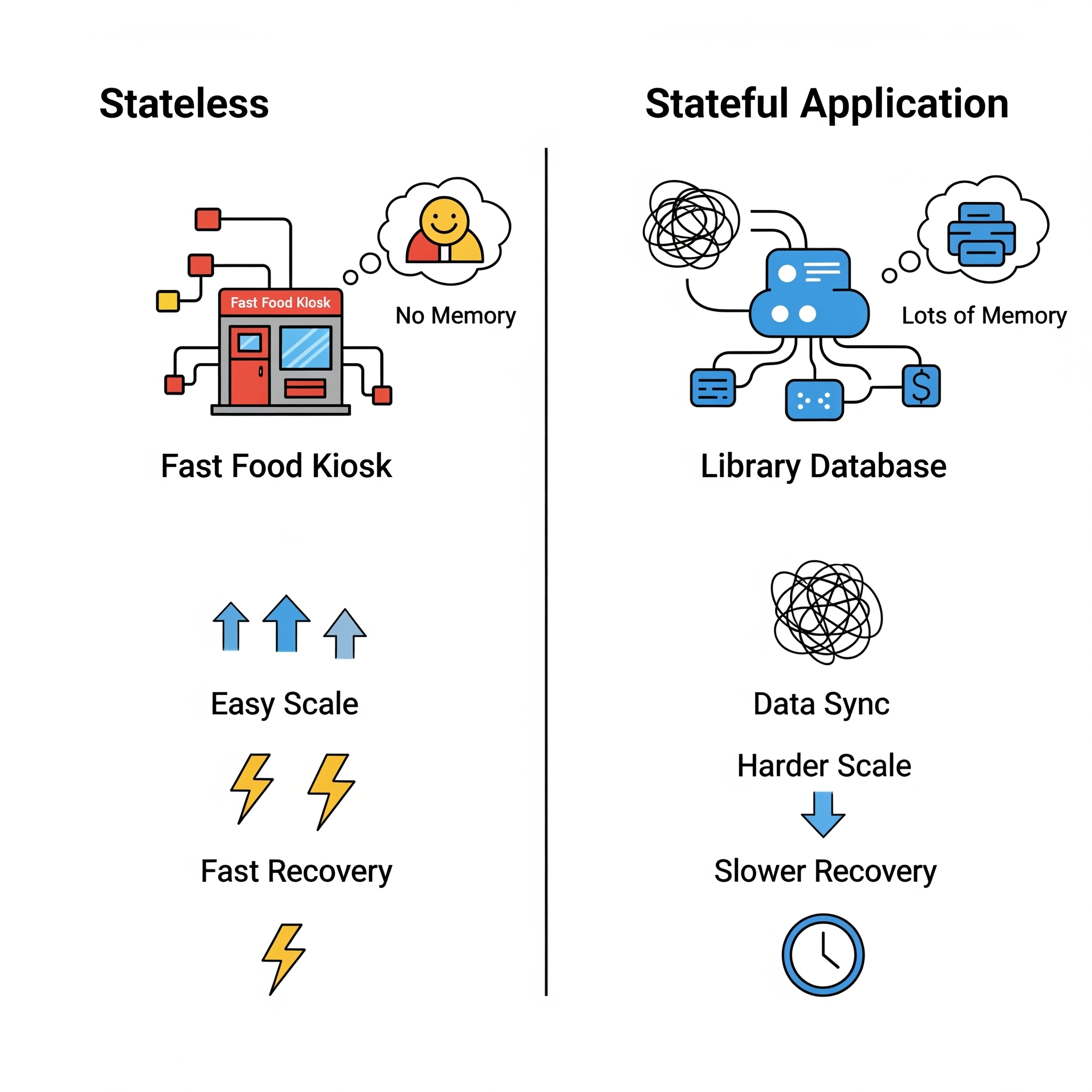
Welcome back to “The Unseen Heroes” series! In our last post, we celebrated the “forgetful champions”—stateless applications—and how their lack of memory makes them incredibly agile and easy to recover. Today, we’re tackling their more complex cousins: stateful applications. These are the digital equivalent of that friend who remembers everything—your coffee order from three years ago, that embarrassing story from high school, and every single detail of your last conversation. And while that memory is incredibly useful, it makes recovery a whole different ballgame.

The Memory Keepers: What Makes Stateful Apps Tricky?
Unlike their stateless counterparts, stateful applications are designed to remember things. They preserve client session information, transaction details, or persistent data on the server side between requests. They retain context about past interactions, often storing this crucial information in a database, a distributed memory system, or even on local drives.
Think of it like this:
- Your online shopping cart: When you add items, close your browser, and come back later, your items are still there. That’s a stateful application remembering your session.
- A multiplayer online game: The game needs to remember your character’s progress, inventory, and position in the world, even if you log out and back in.
- A database: The ultimate memory keeper, storing all your critical business data persistently.
This “memory” is incredibly powerful, but it introduces a unique set of challenges for automated recovery:
- State Management is a Headache: Because they remember, stateful apps need meticulous coordination to ensure data integrity and consistency during updates or scaling operations. It’s like trying to keep a dozen meticulous librarians perfectly in sync, all updating the same book at the same time.
- Data Persistence is Paramount: Containers, by nature, are ephemeral—they’re designed to be temporary. Any data stored directly inside a container is lost when it vanishes. Stateful applications, however, need their data to live on, requiring dedicated persistent storage solutions like databases or distributed file systems.
- Scalability is a Puzzle: Scaling stateful systems horizontally is much harder than stateless ones. You can’t just spin up a new instance and expect it to know everything. It requires sophisticated data partitioning, robust synchronization methods, and careful management of shared state across instances.
- Recovery Time is Slower: The recovery process for stateful applications is generally more complex and time-consuming. It often involves promoting a secondary replica to primary and may require extensive data synchronization to restore the correct state. We’re talking seconds to minutes for well-optimized systems, but it can be longer if extensive data synchronization is needed.
The following image visually contrast the simplicity of stateless recovery with the inherent complexities of stateful recovery, emphasizing the challenges.
The Art of Copying: Data Replication Strategies
Since data is the heart of a stateful application, making copies—or data replication—is absolutely critical. This means creating and maintaining identical copies of your data across multiple locations to ensure it’s always available, reliable, and fault-tolerant. It’s like having multiple identical copies of a priceless historical document, stored in different vaults.
The replication process usually involves two main steps:
- Data Capture: Recording changes made to the original data (e.g., by looking at transaction logs or taking snapshots).
- Data Distribution: Sending those captured changes to the replica systems, which might be in different data centers or even different geographical regions.
Now, not all copies are made equal. The biggest decision in data replication is choosing between synchronous and asynchronous replication, which directly impacts your RPO (how much data you can lose), cost, and performance.
Synchronous Replication: The “Wait for Confirmation” Method
How it works: Data is written to both the primary storage and the replica at the exact same time. The primary system won’t confirm the write until both copies are updated.
The Good: Guarantees strong consistency (zero data loss, near-zero RPO) and enables instant failover. This is crucial for high-stakes applications like financial transaction processing, healthcare systems, or e-commerce order processing where losing even a single record is a disaster.
The Catch: It’s generally more expensive, introduces latency (it slows down the primary application because it has to wait), and is limited by distance (typically up to 300 km). Imagine two people trying to write the same sentence on two whiteboards at the exact same time, and neither can move on until both are done. It’s precise, but slow if they’re far apart.
Asynchronous Replication: The “I’ll Catch Up Later” Method
How it works: Data is first written to the primary storage, and then copied to the replica at a later time, often in batches.
The Good: Less costly, can work effectively over long distances, and is more tolerant of network hiccups because it doesn’t demand real-time synchronization. Great for disaster recovery sites far away.
The Catch: Typically provides eventual consistency, meaning replicas might temporarily serve slightly older data. This results in a non-zero RPO (some data loss is possible). It’s like sending a copy of your notes to a friend via snail mail – they’ll get them eventually, but they won’t be perfectly up-to-date in real-time.
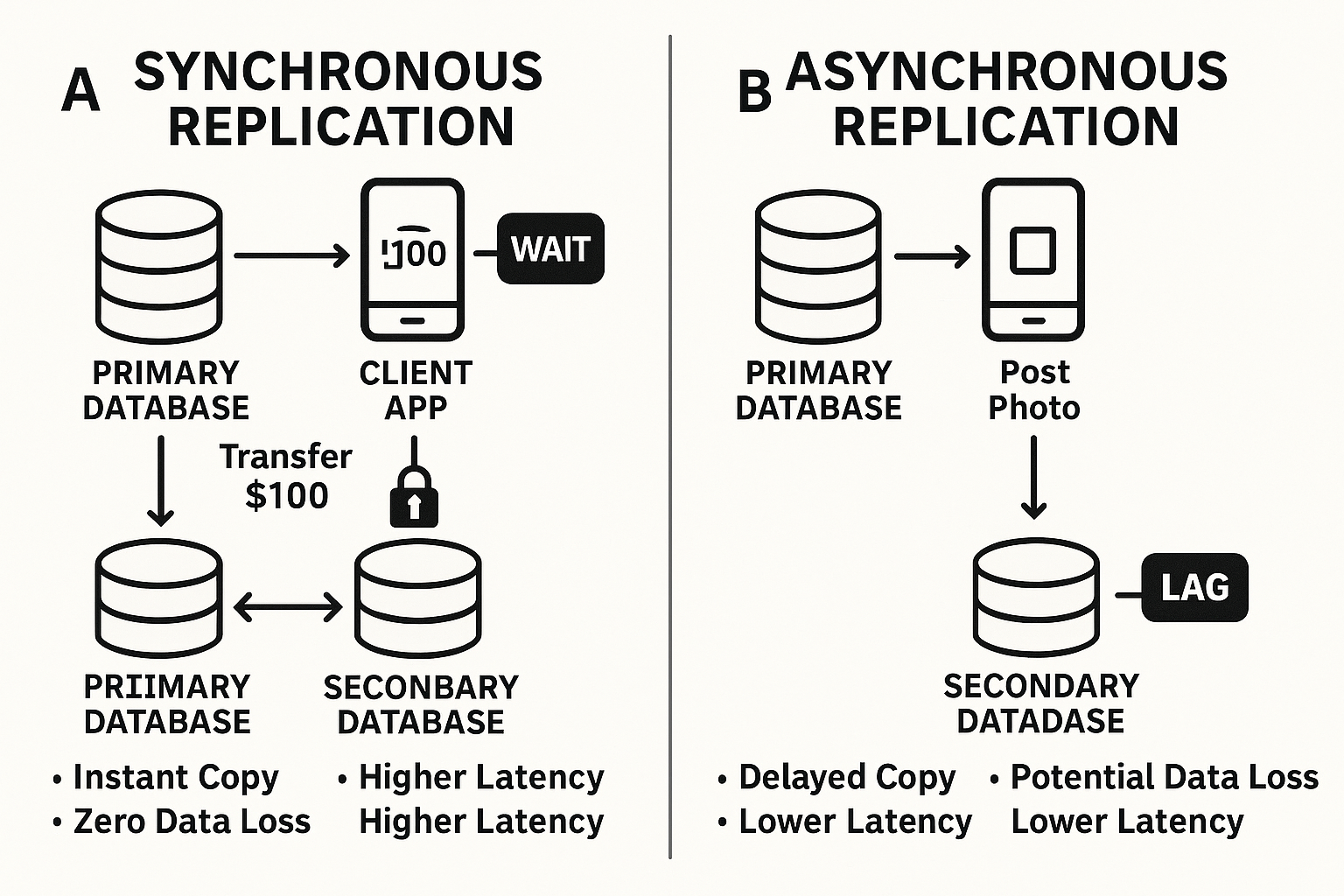
The above diagram clearly illustrates the timing, consistency, and trade-offs of synchronous vs. asynchronous replications.
Beyond synchronous and asynchronous, there are various specific replication strategies, each with its own quirks:
- Full Table Replication: Copying the entire database. Great for initial setup or when you just need a complete snapshot, but resource-heavy.
- Log-Based Incremental Replication: Only copying the changes recorded in transaction logs. Efficient for real-time updates, but specific to certain databases.
- Snapshot Replication: Taking a point-in-time “photo” of the data and replicating that. Good for smaller datasets or infrequent updates, but not real-time.
- Key-Based Incremental Replication: Copying changes based on a specific column (like an ID or timestamp). Efficient, but might miss deletions.
- Merge Replication: Combining multiple databases, allowing changes on all, with built-in conflict resolution. Complex, but offers continuity.
- Transactional Replication: Initially copying all data, then mirroring changes sequentially in near real-time. Good for read-heavy systems.
- Bidirectional Replication: Two databases actively exchanging data, with no single “source.” Great for full utilization, but high conflict risk.
The key takeaway here is that for stateful applications, you’ll likely use a tiered replication strategy, applying synchronous methods for your most mission-critical data (where zero RPO is non-negotiable) and asynchronous for less time-sensitive workloads.
Orchestrating the Chaos: Advanced Consistency & Failover
Simply copying data isn’t enough. Stateful applications need sophisticated conductors to ensure everything stays in tune, especially during a crisis.
Distributed Consensus Algorithms
These are the “agreement protocols” for your distributed system. Algorithms like Paxos and Raft help disparate computers agree on critical decisions, even if some nodes fail or get disconnected. They’re vital for maintaining data integrity and consistency across the entire system, especially during failovers or when a new “leader” needs to be elected in a database cluster.
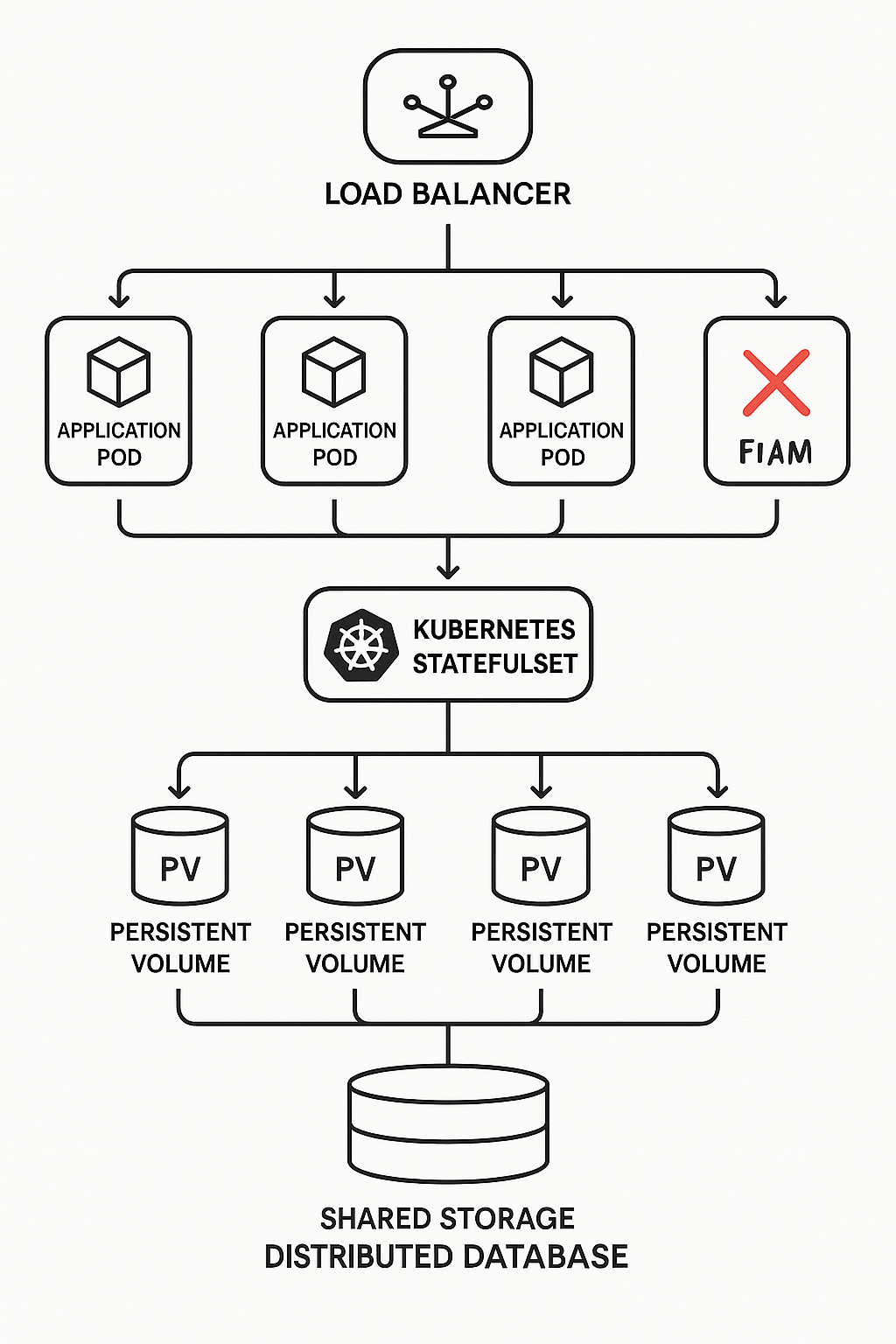
Kubernetes StatefulSets
For stateful applications running in containers (like databases or message queues), Kubernetes offers StatefulSets. These are specifically designed to manage stateful workloads, providing stable, unique network identifiers and, crucially, persistent storage for each Pod (your containerized application instance).
- Persistent Volumes (PVs) & Persistent Volume Claims (PVCs): StatefulSets work hand-in-hand with PVs and PVCs, which are Kubernetes’ way of providing dedicated, durable storage that persists even if the Pod restarts or moves to a different node. This means your data isn’t lost when a container dies.
- The Catch (again): While StatefulSets are powerful, Kubernetes itself doesn’t inherently provide data consistency or transactional guarantees. That’s still up to your application or external tools. Also, disruptions to StatefulSets can take longer to resolve than for stateless Pods, and Kubernetes doesn’t natively handle backup and disaster recovery for persistent storage, so you’ll need third-party solutions.
Decoupling State and Application Logic
This is a golden rule for modern stateful apps. Instead of having your application directly manage its state on local disks, you separate the application’s core logic (which can be stateless!) from its persistent data. The data then lives independently in dedicated, highly available data stores like managed databases or caching layers. This allows your application instances to remain ephemeral and easily replaceable, while the complex job of state management, replication, and consistency is handled by specialized data services. It’s like having a separate, highly secure vault for your important documents, rather than keeping them scattered in every office.
So, while stateful applications bring a whole new level of complexity to automated recovery, the good news is that modern architectural patterns and cloud-native tools provide powerful ways to manage their “memory” and ensure data integrity and availability during failures. It’s about smart design, robust replication, and leveraging the right tools for the job.
In our next blog post, we’ll zoom out and look at the cross-cutting components that are essential for any automated recovery framework, whether you’re dealing with stateless or stateful apps. We’ll talk about monitoring, Infrastructure as Code, and the different disaster recovery patterns. Stay tuned!
Leave a Reply