After seven years of managing high-traffic live streams, you learn that the biggest challenges aren’t usually the video codecs—they are the “invisible” layers: filesystem synchronization, HTTP header inheritance, and metadata consistency.
When you scale from a single server to a cluster of distribution nodes behind a Load Balancer (LB), the margin for error disappears. Here are the core lessons learned from troubleshooting a production-scale HLS environment.
1. The “Last-Modified” Lie and LB Skew
In a multi-server setup (we use 5 distribution nodes), your player is constantly rotating between different IPs. If you use lsyncd or rsync to push files from a source to these nodes, you will encounter Sync Skew.
Even with a 0-second delay, one server might receive the latest .m3u8 playlist 500ms before another. If a player hits Server A and then Server B, and Server B is slightly behind, the player sees a Last-Modified timestamp that is “older” than the previous one. This triggers Stall Detection in the player (often seen as manifestAgeMs jumping between 20s and 70s), even if the stream is technically healthy.
The Lesson: Don’t let the player rely on the file’s “birth certificate.” Force the player to judge the stream by its actual content (the Media Sequence) by suppressing metadata headers and using aggressive cache control.
location /livestream/ { alias /var/www/liveout/;
# HLS Playlists must never be cached by the LB or the Player add_header Cache-Control "no-cache, no-store, must-revalidate, max-age=0" always; expires -1;
# Kill the headers that cause false "Stall" detections add_header Last-Modified ""; add_header ETag ""; if_modified_since off;
open_file_cache off; include cors_support; }
2. The Nginx Inheritance Trap (CORS)
This is a silent killer. In Nginx, if you define an add_header directive in a parent location and then define anyadd_header in a nested child location, the child does not inherit the parent’s headers.
If you optimize your .ts segments for caching but forget to re-include your CORS headers inside that specific block, your player will fetch the playlist successfully but then fail to download the actual media segments due to a CORS error.
The Lesson: Always re-include your cors_support and use the always flag. The always flag ensures that even if a segment is briefly missing (404), the CORS headers are sent, allowing the player to see the 404 instead of throwing a confusing “CORS blocked” error.
location ~* \.ts$ { # Re-include CORS because we are adding Cache-Control headers here include cors_support;
# Segments are immutable; cache them forever add_header Cache-Control "max-age=31536000, public, immutable" always; expires 1y;
# File handle caching is safe for segments open_file_cache max=1000 inactive=20s; }
3. The “Two Masters” Conflict in rtmp.conf
A common mistake is trying to “help” Nginx-RTMP by giving it an application block for every stream type. In our setup, we found that we have an application app_audio block with hls on; while a separate FFmpeg script was writing audio HLS directly to the same disk. This was causing random failures in generating the audio segments.
Nginx-RTMP has a built-in “Garbage Collector” (hls_cleanup). If it sees files in its hls_path that it didn’t specifically create (because FFmpeg wrote them directly), it will delete them. To the admin, it looks like files are vanishing into thin air.
The Lesson: If your FFmpeg script is handling the HLS generation (which is often necessary to satisfy strict Apple AVPlayer requirements for audio-only streams), remove the application block from Nginx-RTMP entirely.
Correct Lean rtmp.conf Logic:
Application Ingest: Receives the stream and triggers the script.
Application Video: Receives the transcoded RTMP push for video HLS.
Audio: No application block. Let FFmpeg own the directory and the filesystem.
4. The rsync Trap: --size-only
When syncing HLS manifests to distribution nodes, it is tempting to use --size-only to speed up transfers. Do not do this. An HLS manifest often retains the same file size even when the content changes (e.g., by swapping one 12-second segment URL for another). rsync with --size-only will detect identical byte counts and skip the sync, leaving your distribution nodes with stale playlists.
The Lesson: Stick to the default mtime (modification time) checks. On a high-performance instance like a DigitalOcean C4 Droplet, the overhead is negligible, but reliability is everything.
Summary: The Good, the Bad, and the Buffering
Split your caching: Playlists get max-age=0; Segments get immutable.
Explicit CORS: Nginx inheritance is not your friend. Re-include headers in nested blocks.
One Master per Folder: If FFmpeg writes the HLS, Nginx-RTMP should stay out of the way.
Atomic Sync: Use lsyncd with delay = 0 and compress = false for the lowest possible latency across your Load Balancer.
By following these principles, you ensure that strict players – especially Apple’s AVPlayer – receive a stream that is consistent, fresh, and compliant with the HLS spec.
There’s a particular kind of panic that sets in when you SSH into a production server and see this:
load average: 45.63, 38.37, 28.93
On a 2-core machine, that’s not just high — it’s catastrophic.
I usually help one of my friends with LAMP servers hosted on DigitalOcean that run WooCommerce. The site brings in good sales for his business. Recently, he reached out to me to say that some of his customers reported slow order placement. When I logged into the server, I found an interesting pattern.
This post walks through a real debugging session using a symptoms → diagnostics → solution approach. Along the way, we’ll uncover multiple overlapping issues (not just one), fix them step by step, and explain why architectural changes like PHP-FPM and Nginx matter.
Symptoms: What went wrong
The server started showing:
Extremely high load averages (45+ on a 2-core system)
The key observation from this is that the process kswapd0 is consuming 35% CPU. This is not normal. It means the kernel is struggling with memory pressure.
2. Apache process explosion
# ps aux | grep apache | wc -l 14
RSS is the actual physical RAM a process is using right now, measured in KB. It does NOT include swapped-out memory, so it represents memory currently resident in RAM. It is the single most important metric for sizing concurrency.
In the output, I saw that the RSS is approximately 200MB – 260MB for each Apache process.
So for 14 processes it is:
14 processes × ~220MB ≈ ~3GB RAM
On a 4GB system, that’s quite high.
3. MySQL check (surprisingly clean)
When I checked the full process list on the MySQL
mysql> SHOW FULL PROCESSLIST;
I found it clean, with a few sleep connections and no long-running queries. I verified it with
# mysqladmin processlist
and found a similar output. So MySQL wasn’t the bottleneck.
4. Network state – hidden problem
The netstat revealed a hidden problem that may be contributing to the sluggishness.
In this case, vmstat was the most powerful tool run. In the output,
r is the number of runnable processes (waiting for CPU). Ideally, it should have a value less than or equal to the number of CPU cores. A value exceeding the number of available CPU cores on the machine would indicate CPU contention.
id indicates a percentage of CPU that is idle. A value typically in the range of 70-100% indicate a relaxed system. A low value (say 0-20%) indicates a busy CPU. However, 0% means it is fully saturated.
si and so are swapped in and out. A value of 0 indicates no swapping and is considered good. Occasionally, a value > 0 indicates mild pressure. But if this value remains above 0 continuously, it may indicate memory problems.
So when I ran:
# vmstat 1 5
Output (trimmed):
r b swpd free si so us sy id
14 0 0 399400 0 0 34 29 35
15 0 0 362864 0 0 87 12 0
r with a value of 14-15 indicates too many runnable processes, and id with 0 means CPU is fully saturated.
After initial fixes, when I ran vmstat again, I saw the new numbers:
r b swpd free si so us sy id
1 0 12120 2554084 0 0 34 29 35
0 0 12120 2554084 0 0 0 1 99
So, now a value of r between 0-2 indicates a healthy condition, an id of 86-89% indicate idle CPU, and a si/so of 0 indicates no swapping.
r = 0–2 → healthy
id = 86–99% → CPU idle
si/so = 0 → no swapping
Three Root Causes
This wasn’t a single issue. It was a stacked failure:
1. Apache (mod_php) memory bloat
Each request = full Apache process
Each process ≈ 200MB+
Too many workers → RAM exhaustion
2. Swap thrashing (kswapd0)
Memory filled up
Kernel started reclaiming memory
CPU burned by swap management
3. Connection pressure (SYN_RECV flood)
121 half-open connections
Apache workers are tied up waiting
Solutions Applied
1. SYN flood mitigation (UFW + kernel)
I enabled:
net.ipv4.tcp_syncookies=1
And:
ufw limit 80/tcp
ufw limit 443/tcp
2. Apache concurrency control
Reduced workers:
MaxRequestWorkers 6
This helped stabilize the CPU with no process pile-up
3. KeepAlive tuning
KeepAlive On
MaxKeepAliveRequests 50
KeepAliveTimeout 2
4. OPcache verification and tuning
When PHP runs a script, it parses PHP code, compiles it into bytecode, and executes it. Without OPcache, this happens on every request.
With OPcache enabled, compiled bytecode is stored in memory so that future requests can reuse it. Without OPcache, high CPU usage and slower response times are expected. With OPcache, 30-35% less CPU is used, and execution is faster.
When I checked, I found that OPcache (opcache.enable) was already enabled in the php.ini.
I would want to replace mod_php with php-fpm. In mod_php, each Apache process embeds PHP, leading to high memory usage (~200 MB per worker). This results in poor scalability and a lack of separation of concerns.
PHP-FPM, on the other hand, runs as a separate service and has lightweight workers (~20-40 MB), providing better process control and supporting pooling and scaling. This will result in lower memory usage, better CPU efficiency, and more predictable performance.
2. Prefer Nginx Over Apache
Now, this is not about nginx hype; it’s about an architectural choice. I have been using Apache for quite some time and love it. The pre-fork model of Apache has a process/thread per connection, is memory-heavy, and struggles under concurrency.
Nginx, with its event-driven model, can handle thousands of connections with a few processes and non-blocking I/O, making it an ideal choice for modern web workloads.
Finally
What looked like a “CPU problem” turned out to be:
Memory exhaustion
Connection pressure
Poor process model
Fixing it required layered thinking, not just tweaking one parameter.
And the biggest lesson?
One can tune one’s way out of trouble temporarily, but the real win comes from choosing the right architecture.
So, now, if you’ve ever seen load averages that made no sense, this pattern might look familiar. And now you know exactly how to break it down.
We rarely notice how much of what we believe rests on things we cannot directly see. Science asks us to accept entities, forces, and structures that appear only through their effects. Philosophy steps in at this point, not to question science, but to ask what makes such a belief reasonable in the first place.
When Inference Justifies Belief
We live surrounded by things we cannot directly experience. Atoms, black holes, gravity, even other minds. Our senses reveal only a thin slice of reality, yet we form beliefs about what lies beyond.
So the real question is not whether we can see something. The question is when believing the unseen becomes reasonable.
The whole of science is nothing more than a refinement of everyday thinking.
Human perception evolved for survival, not truth. We see objects at the human scale, but the microscopic, the cosmic, and the abstract remain hidden.
Human perception is selective. It filters rather than reveals. What we experience is already interpreted by cognitive models that prioritise usefulness over completeness. Colour, solidity, and continuity are not properties we perceive directly at the fundamental level. They are stable interpretations that help us navigate the world.
In this sense, the gap between appearance and reality is not unusual. It is the normal condition of knowing. Science does not introduce that gap. It makes it explicit and tries to bridge it.
For example, a table appears solid, yet physics describes it as mostly empty space structured by forces. The difference is not an error in perception, but a difference in explanatory level.
Science begins where perception fails.
Human senses reveal the visible world, while science uncovers hidden layers of reality.
We believe in many things we cannot see because they explain the world better than anything else.
Indirect evidence works
We never see electrons directly. Yet their existence explains chemical bonds, electricity, and modern technology.
Experiments do not show electrons themselves. They show patterns that make electrons the best explanation. The double slit experiment is a powerful example. What we observe is behaviour, not the object itself.
Much of scientific knowledge relies on instruments that extend perception. Microscopes, detectors, and sensors do not simply show hidden objects. They translate interactions into signals that must be interpreted. What scientists observe is rarely the entity itself, but the trace it leaves.
This makes inference unavoidable. We move from effects to causes, from measurements to models. The strength of indirect evidence lies in repeatability. When different experiments produce compatible traces, confidence grows even without direct observation.
This is why entities like electrons feel less speculative than they might appear. They participate in explanations across chemistry, physics, and engineering. Their reality is supported by how much of the world becomes intelligible once they are assumed.
Indirect evidence is often stronger than direct perception.
Electrons are inferred from experimental patterns rather than directly observed.
Science often works by trusting indirect evidence, not direct observation.
When theory becomes real
Black holes began as mathematical objects in relativity. For decades, they were theoretical objects.
Over time, different lines of evidence converged. Gravitational waves. Stellar motion. Telescope images. Theory moved into observation.
This transition from theory to observation is rarely sudden. It is gradual and often messy. Early evidence reduces uncertainty rather than eliminating it, and competing interpretations may coexist for years, sometimes decades.
A well-known example is the debate over the nature of light. For centuries, scientists disagreed about whether light was a wave or a particle. Different experiments supported different interpretations, and neither framework fully displaced the other. With the development of quantum mechanics, a new account emerged, showing that light behaves in ways that do not fit neatly into either category. Competing interpretations persisted because each explained part of the evidence.
A similar pattern appears in cosmology. Observations revealed that galaxies are moving away from each other, yet scientists disagreed about why. Some explanations focused on the universe’s initial conditions, while others introduced new concepts such as dark energy. For years, multiple explanations coexisted as evidence accumulated and models were refined.
What changes over time is not a single decisive moment, but the accumulation of constraints. As measurements improve, the space of plausible alternatives narrows. Eventually, the theoretical entity becomes the most stable explanation available.
Black holes illustrate this process clearly. They were first mathematical possibilities, then astrophysical hypotheses, and finally observational targets. Each stage relied on inference before confirmation.
Inference allowed belief long before confirmation arrived.
Black holes show how inference can precede direct evidence.
The invisible becomes real when evidence converges from different directions.
The core idea — Inference to the best explanation
Science does not accept ideas randomly. It compares explanations.
When we observe patterns, there are usually multiple ways to explain them. Some explanations are narrow, some are complicated, and some fail when new evidence appears. Scientific reasoning works by weighing these possibilities rather than committing too quickly.
An explanation becomes reasonable when it explains observations better than alternatives, generates predictions, fits with what we already know, and cannot be replaced by a simpler rival. The strength of an idea lies not in being imaginable, but in doing explanatory work.
Philosophers call this process inference to the best explanation. We infer that something exists because it makes the world more understandable than competing accounts.
Many central scientific ideas emerged this way. Gravity was accepted long before its mechanism was understood because it explained motion across the heavens and the earth with remarkable consistency. Today, dark matter occupies a similar position. It has not been directly observed, yet it explains patterns that otherwise remain puzzling.
Inference does not guarantee truth. It provides the most reasonable belief available given current evidence. Science moves forward by trusting the explanation that works best, while remaining open to replacement when a better one appears.
Scientific belief emerges when an explanation is selected that best fits the evidence.
Inference is not guessing. It is disciplined explanation.
The frontier — dark matter
Galaxies rotate in ways that visible matter cannot explain. Something unseen appears to influence gravity.
Dark matter is compelling because the same discrepancy appears in multiple contexts. Galaxy rotation curves, gravitational lensing, and large-scale structure all suggest the presence of more mass than we can see. The consistency of this pattern is what gives the idea weight.
At the same time, dark matter remains a frontier because alternative explanations are still explored. Modified gravity theories attempt to explain the same observations without introducing new entities. This is exactly how science should operate. Competing explanations sharpen inference.
The interesting philosophical point is that belief here is graded rather than binary. Scientists treat dark matter as the best current explanation while actively searching for ways it might be wrong.
Dark matter has not been directly detected. Yet its effects are consistent across observations.
Science often believes before it sees.
Dark matter is inferred from gravitational effects rather than direct observation.
Dark matter shows that science is comfortable believing before seeing.
The boundary of reason
Not every unseen claim deserves belief. Some ideas cannot be tested, predicted, or explained.
An undetectable object that leaves no trace explains nothing. It does not compete with scientific explanations.
Testability marks the boundary between inference and speculation.
The distinction is not between visible and invisible. It is between explanatory and non-explanatory posits. An unseen entity becomes reasonable when removing it makes our understanding worse. If nothing changes when the entity is removed, the posit does no work.
This is why unfalsifiable claims struggle within scientific reasoning. They cannot be constrained by evidence and therefore cannot improve explanations. Science does not reject them because they are invisible, but because they do not participate in the cycle of refinement.
Testability, in this sense, is less about immediate experiments and more about vulnerability. Reasonable ideas risk being wrong.
Reasonable beliefs require explanations that can be tested against evidence.
Not every explanation deserves belief. Testability draws the boundary.
The inference cycle
Belief in science is not permanent. It is iterative.
This iterative structure explains why scientific belief feels both stable and revisable. Stability comes from repeated success. Revision comes from the expectation that explanations are provisional.
Importantly, the cycle operates at multiple timescales. Some explanations change quickly, others remain stable for centuries. What matters is not permanence but performance. An explanation earns trust by continuing to organise experience effectively.
Inference, therefore, functions less like a single decision and more like an ongoing commitment. We act as if an explanation is true while remaining prepared to update it.
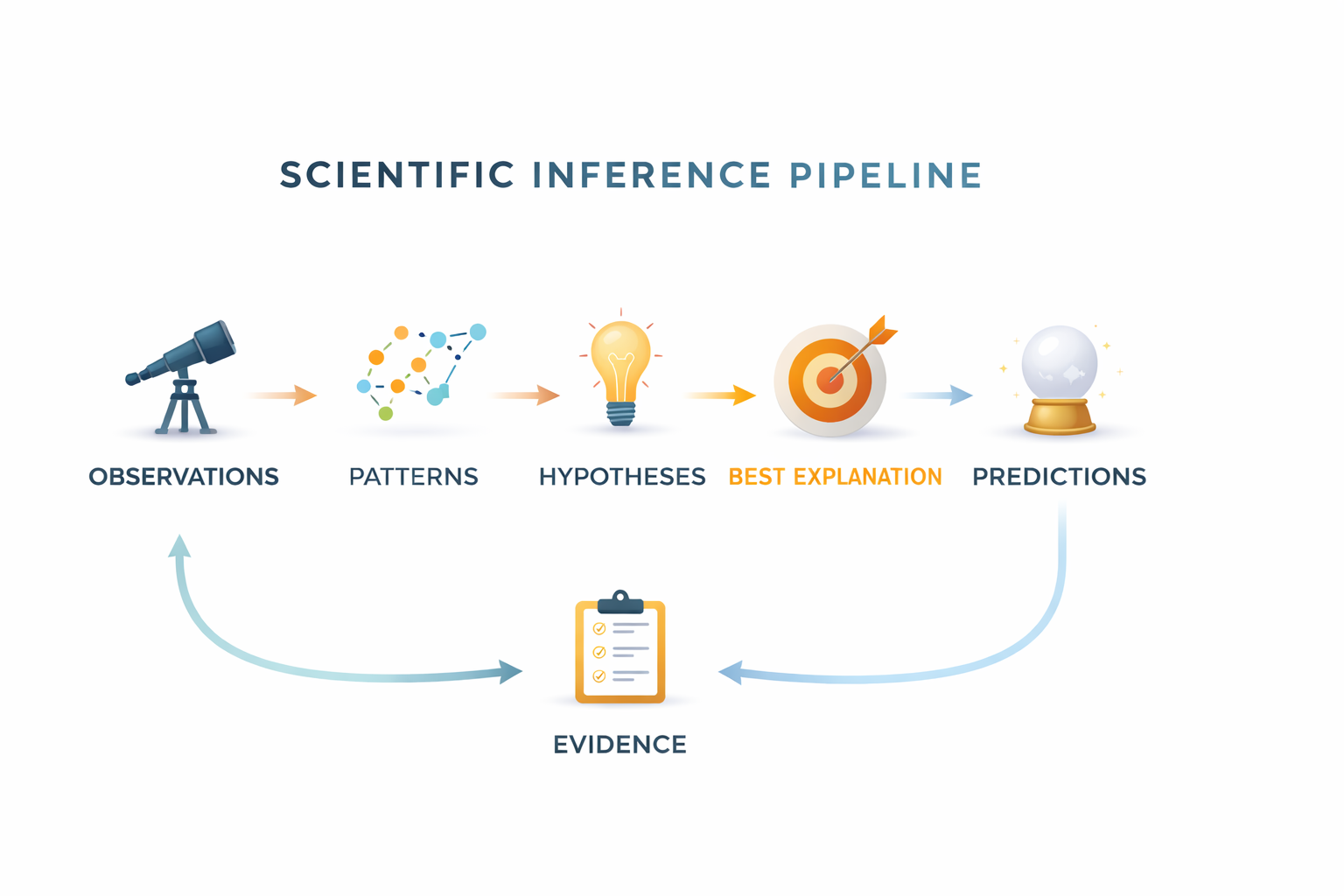
Observation leads to patterns. Patterns lead to hypotheses. The best explanation generates predictions. New evidence either strengthens or replaces the belief.
This cycle makes scientific belief dynamic rather than absolute.
Scientific belief evolves through a continuous cycle of explanation and evidence.
Scientific belief is provisional. It lasts until a better explanation appears.
Resolution — why inference justifies belief
We accept the unseen when evidence demands it. When patterns persist. When explanations predict. When knowledge becomes more coherent.
Inference allows us to move beyond the limits of perception without abandoning reason.
Belief in science is not about certainty. It is about the best explanation available right now.
And that is enough to act, to build, and to understand the invisible world.
Seen this way, inference is not a weakness of knowledge but its primary engine. Direct observation alone would leave most of reality inaccessible. Explanation allows us to extend understanding beyond immediate experience without abandoning discipline.
The philosophical significance is broader than science. Every day reasoning follows the same pattern. We infer intentions from behaviour, causes from outcomes, and structures from patterns. Scientific inference is a refined version of a familiar cognitive move.
The same structure appears outside science. Religious belief, too, often operates through inference, drawing conclusions from experience, coherence, and explanatory scope rather than direct observation. Traditions can be understood as competing interpretations of shared human phenomena, each attempting to make sense of consciousness, value, suffering, and order. Whether these inferences should be evaluated like scientific ones or according to different standards is a question that opens the next stage of this conversation.
Knowledge advances when we follow patterns, trust explanations, and remain open to better evidence.
Every few years, a new wave of artificial intelligence captures public attention. Chatbots start sounding more natural. Machines write poems, code, and essays. Some even offer emotional support. And inevitably, the same question resurfaces:
“Has AI finally become intelligent?”
Often, this question is framed in terms of a famous benchmark proposed more than seventy years ago, the Turing Test. If a machine can talk like a human, does that mean it thinks like one?
As someone who works closely with technology, I’ve found that the answer is far more complicated than it first appears.
From Philosophy to Observable Behavior
In 1950, British mathematician and computer scientist Alan Turing published a groundbreaking paper titled “Computing Machinery and Intelligence.” In it, he proposed what later became known as the Turing Test.
Rather than arguing about abstract definitions of “thinking,” Turing suggested a simple experiment:
A human judge communicates through text with two unseen participants—one human and one machine. If the judge cannot reliably tell which is which, the machine is said to have passed the test.
Turing’s idea was revolutionary for its time. It shifted the conversation from philosophy to observable behavior. Intelligence, he suggested, could be judged by how convincingly a machine behaved in human conversation.
Why Passing the Test Feels So Impressive
When an AI passes something like the Turing Test, it demonstrates several remarkable abilities:
It can use natural language fluently
It responds appropriately to context
It adapts to tone and emotion
It maintains long, coherent conversations
To most people, this feels like intelligence. After all, language is one of our strongest markers of human cognition. If something talks like us, we instinctively assume it thinks like us.
Modern language models amplify this effect. They can discuss philosophy, explain technical concepts, and even joke convincingly. In short interactions, they often feel “alive.”
But appearance is not reality.
But Imitation is Not Reality
One of the strongest critiques of the Turing Test comes from philosopher John Searle. In his famous “Chinese Room” thought experiment, Searle imagined a person who manipulates Chinese symbols using a rulebook, without understanding Chinese.
From the outside, the system appears fluent. Inside, there is no comprehension.
The parallel with modern AI is clear: A system can produce correct, fluent answers without grasping their meaning.
It processes patterns, not concepts.
There are several other limitations in the Turing Test.. The Turing Test is essentially an “imitation game” that rewards the best liar. By focusing purely on conversation, it ignores the “big picture” of intelligence—like moral reasoning and creativity—while leaving the final verdict up to the mercy of biased human judges. In fields like healthcare or finance, we need transparency, not a machine that’s just good at pretending.
To move beyond the limitations of mere imitation, the industry has developed more rigorous, multi-dimensional benchmarks. This is a shift that defines how AI is evaluated today.
Modern Benchmarks for Machine Intelligence
As AI research matured, scientists moved beyond the Turing Test. Today, intelligence is evaluated across multiple dimensions.
Reasoning Benchmarks
Projects like BIG-bench and the ARC Challenge test logical reasoning, abstraction, and problem-solving.
General Knowledge and Transfer
The Massachusetts Institute of Technology and other institutions study whether AI can generalize knowledge across domains, a core feature of human learning.
Embodied Intelligence
Some labs, including OpenAI, explore how AI behaves in simulated environments, learning through interaction rather than text alone.
Safety and Alignment
Modern evaluations increasingly focus on whether systems behave responsibly and align with human values, not just whether they sound smart.
These approaches reflect a more mature understanding of intelligence.
Why Passing the Turing Test Does Not Mean “Thinking”
Even if an AI consistently fools human judges, it still does not think like a human in any meaningful sense.
1. Patterns vs. Mental Models
AI systems learn by analyzing enormous datasets and predicting likely sequences. They recognize correlations, not causes.
Humans build mental models of the world grounded in experience.
2. No Conscious Awareness
There is no evidence that current AI systems possess subjective awareness. They do not experience curiosity, doubt, or reflection.
Philosopher David Chalmers famously described consciousness as the “hard problem” of science. AI has not come close to solving it.
3. No Intentions or Desires
Humans think in terms of goals, fears, hopes, and values. AI has none of these internally. Any “motivation” is externally programmed.
4. No Moral Responsibility
We hold humans accountable for their actions. We cannot meaningfully do the same for machines. Responsibility always traces back to designers and operators.
The Illusion of Intelligence
While researching for this blog post, I found several references to a book, Artificial Intelligence: A Modern Approach by Stuart Russell and Perter Norvig. The authors note in this book that much of AI’s success comes from exploiting narrow problem structures.
When AI speaks fluently, we instinctively anthropomorphize it. We project personality, intention, and emotion onto it. I think this is a psychological reflex and we confuse convincing behavior with inner life.
Rethinking What Intelligence Really Means
The Turing Test remains historically important. It sparked decades of innovation and philosophical debate. But in today’s context, it feels outdated.
Instead of asking:
“Can machines fool us?”
We should ask:
Can they reason reliably?
Can they support human decision-making?
Can they reduce harm?
Can they enhance creativity and productivity?
These questions matter far more than imitation.
As AI researcher Yann LeCun has often emphasized, intelligence is not just about language, it is about learning, planning, and interacting with the world.
Intelligence Without Illusion
Passing the Turing Test is an impressive technical milestone. It shows how far machine learning and language modeling have progressed.
But it does not mean machines think, understand, or experience the world as humans do.
Today’s AI systems are powerful tools, statistical engines trained on vast amounts of human-generated data. They extend our capabilities, automate tasks, and sometimes surprise us.
They do not possess minds.
The real challenge of AI is not to build perfect human imitators, but to create systems that responsibly complement human intelligence, while respecting the depth, complexity, and fragility of our own.
In the long run, that goal is far more valuable than passing any imitation game.
Have you ever started a new Python project and, within a week, everything already feels messy?
Your config.py file is slowly becoming a dumping ground. There are commented lines everywhere, database URLs hardcoded directly in the file, and if ENV == “prod” conditions scattered across the codebase. At first, it feels manageable. But very quickly, it becomes difficult to understand what is actually being used and what is not.
And somewhere in the back of your mind, there is always that small fear: What if I accidentally expose a production password or push the wrong configuration?
This kind of setup might work for a small script. But as the project grows, it becomes hard to maintain and almost impossible to scale properly. And yes, this still happens even in the modern world of AI-assisted coding, irrespective of which model we use.
Over time, I realized that the cleanest way to handle configuration is not through complex .ini files or deeply nested dictionaries. I prefer using Python class inheritance along with environment variables. In some projects, I also pair this with Pydantic for validation when things get more complex.
Here’s how I structure my configuration systems to keep them type-safe, secure, and, most importantly, easy to read.
The Foundation
First, we need to talk about secrets. Hardcoding a Telegram token inside your code is basically inviting trouble. The simplest solution is to move sensitive values into a .env file and load them from environment variables.
One important rule. Never commit your .env file to Git. Instead, keep a .env.example file with empty placeholders so your team knows what variables are required.
This class holds the defaults. Everything common lives here. No duplication.
When I need environment-specific behavior, I simply inherit and override only what is required.
For example, in end-to-end testing, I might want notifications enabled but routed differently.
class E2EConfig(Config): """Overrides for E2E testing""" TESTING = True TELEGRAM_SEND_NOTIFICATIONS = True E2E_NOTIFICATION_BOT = 'Admin Bot'
For unit or integration testing, I definitely do not want real Telegram messages going out. I also prefer an in-memory database for speed.
class TestConfig(Config): """Overrides for local unit tests""" TESTING = True SQLALCHEMY_DATABASE_URI = 'sqlite:///:memory:' # Use in-memory DB for speed TELEGRAM_SEND_NOTIFICATIONS = False WTF_CSRF_ENABLED = False
Notice something important here. I am not copying the entire base class. I am only overriding what changes. That alone reduces many future mistakes.
To avoid magic strings floating around in the logic layer, I sometimes pair this with enums.
from enum import Enum
class LogType(Enum): STREAM_PUBLISH = 'STREAM_PUBLISH' NOTIFICATION = 'NOTIFICATION'
Now my IDE knows the valid options. Refactoring becomes safer. Typos become less likely.
Loading the configuration is also simple. In Flask, I usually use a factory pattern and switch based on one environment variable.
import os from flask import Flask from config import Config, E2EConfig, TestConfig
def create_app(): app = Flask(__name__)
# Select config based on APP_ENV environment variable env = os.environ.get("APP_ENV", "production").lower()
# Load the selected class app.config.from_object(configs.get(env, Config))
return app
That is it. One variable controls everything. No scattered if-else checks across the codebase.
Over time, this pattern has saved me from configuration-related surprises. All settings live in one place. Inheritance avoids copy-paste errors. Tests do not accidentally spam users because TELEGRAM_SEND_NOTIFICATIONS is explicitly set to False in TestConfig.
And if tomorrow I need a StagingConfig or DevConfig, I just add a small class that extends Config. Three or four lines, and I am done.
Configuration management may not be glamorous, but it decides how stable your application feels in the long run. A clean structure here reduces mental load everywhere else.