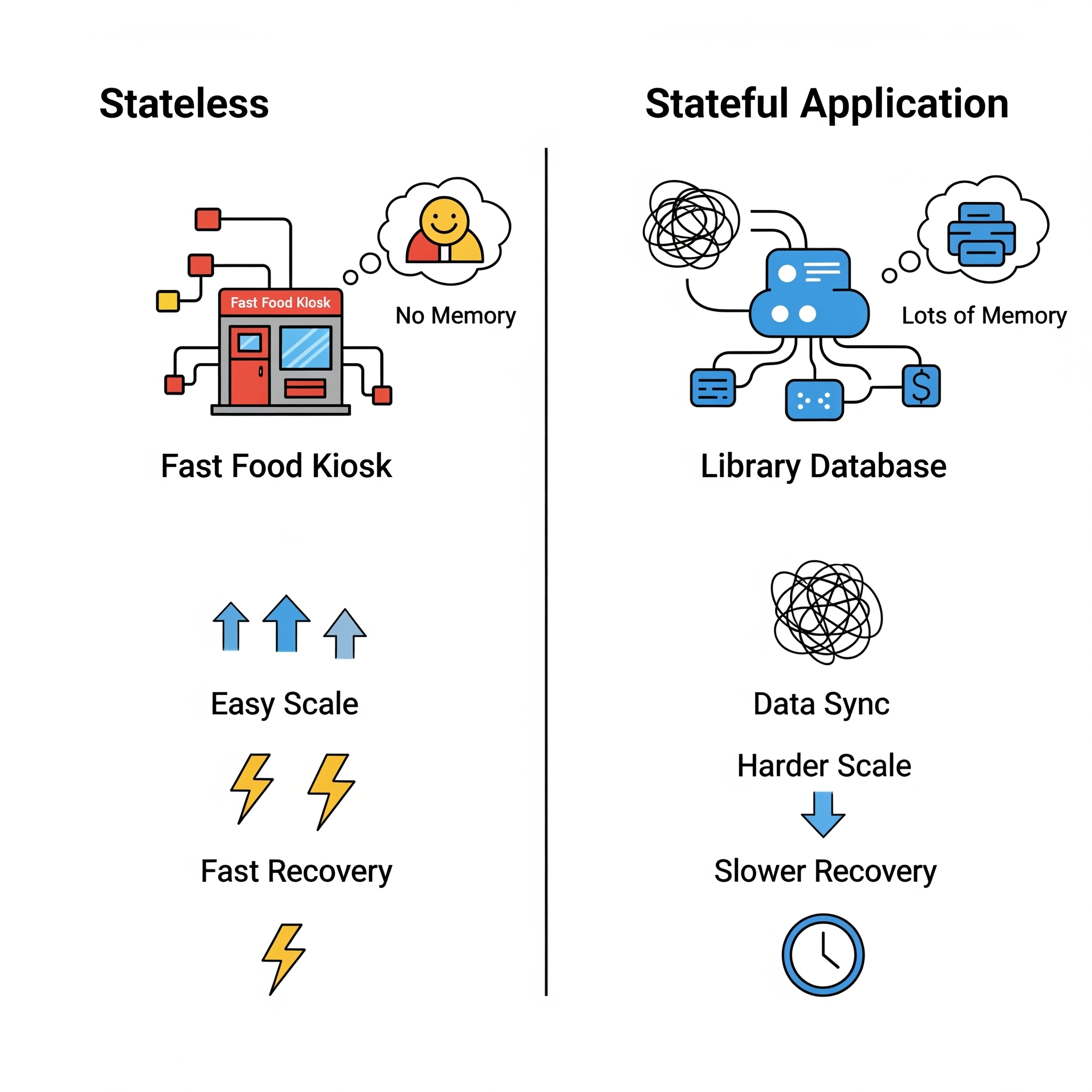
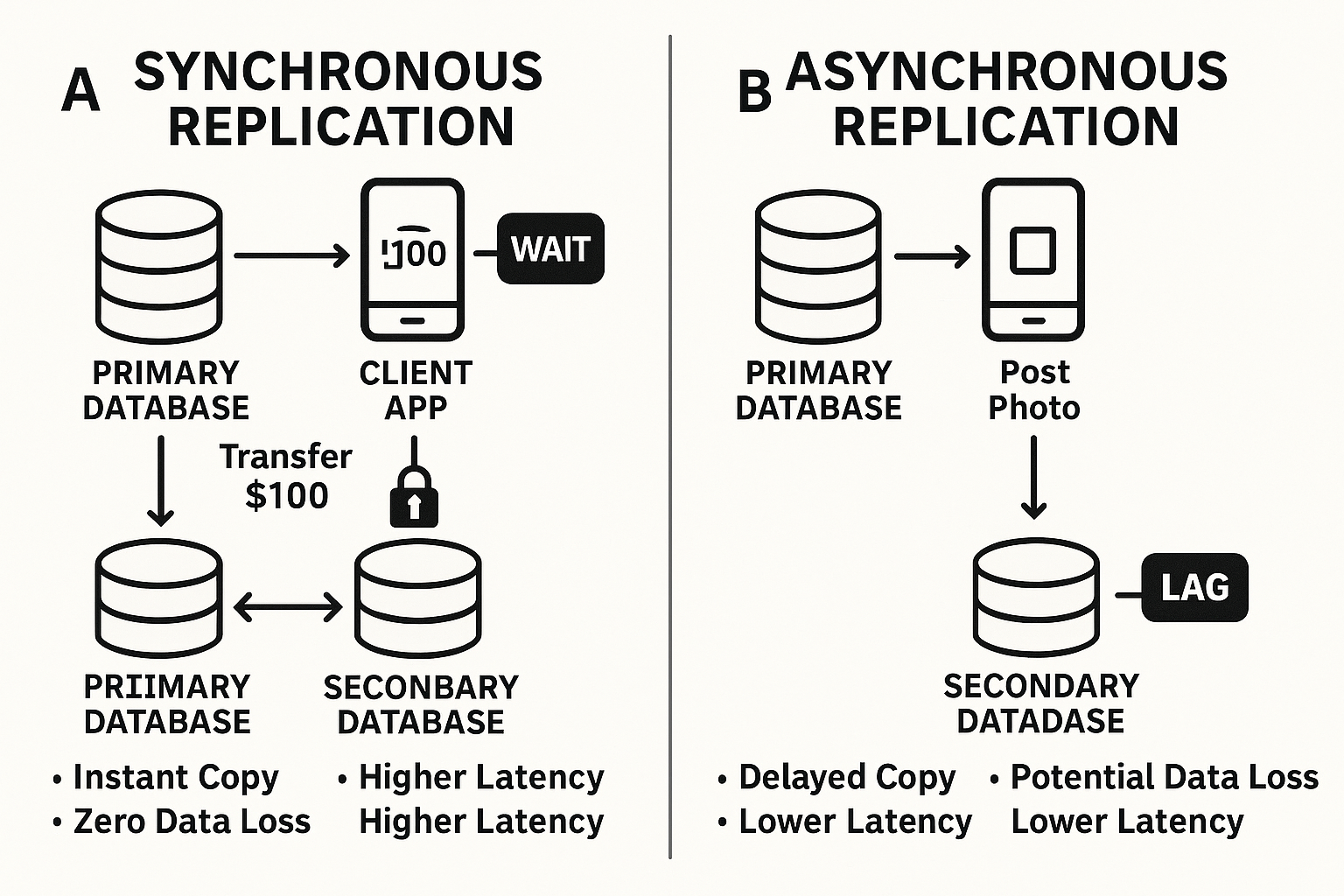
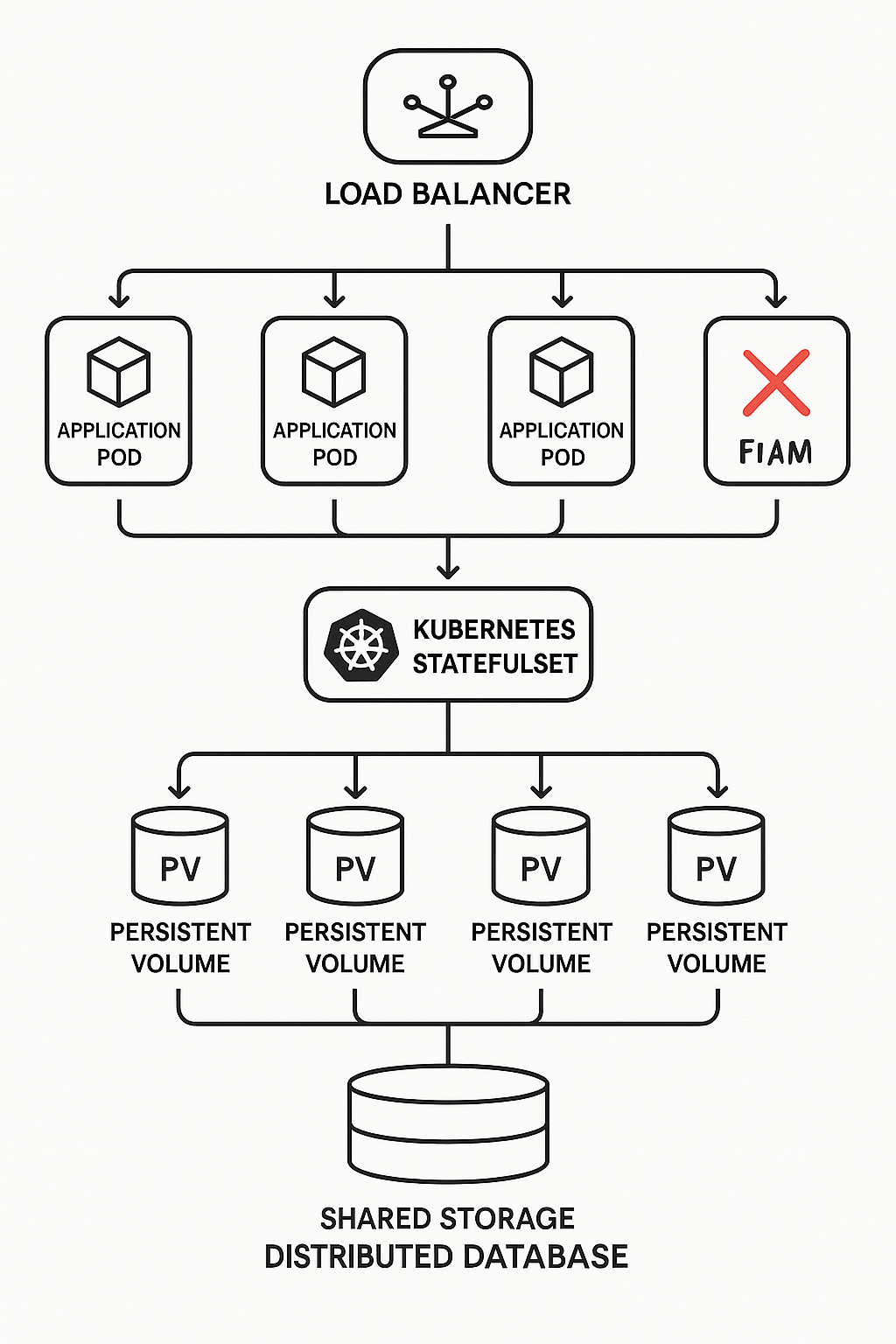
Welcome to the grand finale of our “Unseen Heroes” series! We’ve peeled back the layers of automated system recovery, from understanding why failures are inevitable to championing stateless agility, wrestling with stateful data dilemmas, and mastering the silent sentinels, the tools and tactics that keep things humming.
But here’s the crucial truth: even the most sophisticated tech stack won’t save you if your strategy and, more importantly, your people, aren’t aligned. Automated recovery isn’t just a technical blueprint; it’s a living, breathing part of your organization’s DNA. Today, we go beyond the code to talk about the strategic patterns, the human element, and what the future holds for keeping our digital world truly resilient.
Beyond the Blueprint: Choosing Your Disaster Recovery Pattern
While individual components recover automatically, sometimes you need to recover an entire system or region. This is where Disaster Recovery (DR) Patterns come in – strategic approaches for getting your whole setup back online after a major event. Each pattern offers a different balance of RTO/RPO, cost, and complexity.
The Pilot Light approach keeps the core infrastructure, such as databases with replicated data, running in a separate recovery region, but the compute layer (servers and applications) remains mostly inactive. When disaster strikes, these compute resources are quickly powered up, and traffic is redirected. This method is cost-effective, especially for non-critical systems or those with higher tolerance for downtime, but it does result in a higher RTO compared to more active solutions. The analogy of a stove’s pilot light fits well, you still need to turn on the burner before you can start cooking.
A step up is the Warm Standby model, which maintains a scaled-down but active version of your environment in the recovery region. Applications and data replication are already running, albeit on smaller servers or with fewer instances. During a disaster, you simply scale up and reroute traffic, which results in a faster RTO than pilot light but at a higher operational cost. This is similar to a car with the engine idling, ready to go quickly but using fuel in the meantime.
At the top end is Hot Standby / Active-Active, where both primary and recovery regions are fully functional and actively processing live traffic. Data is continuously synchronized, and failover is nearly instantaneous, offering near-zero RTO and RPO with extremely high availability. However, this approach involves the highest cost and operational complexity, including the challenge of maintaining data consistency across active sites. It is akin to having two identical cars driving side by side, if one breaks down, the other seamlessly takes over without missing a beat.
The Human Element: Building a Culture of Resilience
No matter how advanced your technology is, true resilience comes from people—their preparation, mindset, and ability to adapt under pressure.
Consider a fintech company that simulates a regional outage every quarter by deliberately shutting down its primary database in Region East. The operations team, guided by clear runbooks, seamlessly triggers a failover to Region West. The drill doesn’t end with recovery; instead, the team conducts a blameless post-incident review, examining how alerts behaved, where delays occurred, and what could be automated further. Over time, these cycles of testing, reflection, and improvement create a system—and a team—that bounces back faster with every challenge.
Resilience here is not an endpoint but a journey. From refining monitoring and automation to conducting hands-on training, everyone on the team knows exactly what to do when disaster strikes. Confidence is built through practice, not guesswork.
Key elements of this culture include:
- Regular DR Testing & Drills – Simulated outages and chaos engineering to uncover hidden issues.
- Comprehensive Documentation & Runbooks – Clear, actionable guides for consistent responses.
- Blameless Post-Incident Reviews – Focus on learning rather than blaming individuals.
- Continuous Improvement – Iterating on automation, alerts, and processes after every incident.
- Training & Awareness – Equipping every team member with the knowledge to act swiftly.
A Story of Tomorrow’s Recovery Systems
It’s 2 a.m. at Dhanda-Paani Finance Ltd, a global fintech startup. Normally, this would be the dreaded hour when an unexpected outage triggers panic among engineers. But tonight, something remarkable happens.
An AI-powered monitoring system quietly scans millions of metrics and log entries, spotting subtle patterns—slightly slower database queries and minor memory spikes. Using machine learning models trained on historical incidents, it predicts that a failure might occur within the next 30 minutes. Before anyone notices, it reroutes traffic to a healthy cluster and applies a preventive patch. This is predictive resilience in action – the ability of AI/ML systems to see trouble coming and act before it becomes a real problem.
Minutes later, another microservice shows signs of a memory leak. Rather than waiting for it to crash, Dhanda-Paani’s self-healing platform automatically spins up a fresh instance, drains traffic from the faulty one, and applies a quick fix. No human intervention is needed. It’s as if the infrastructure can diagnose and repair itself, much like a body healing a wound.
All the while, a chaos agent is deliberately introducing small, controlled failures in production, shutting down random containers or delaying network calls, to test whether every layer of the system is as resilient as it should be. These proactive tests ensure the platform remains robust, no matter what surprises the real world throws at it.
By morning, when the engineers check the dashboards, they don’t see outages or alarms. Instead, they see a series of automated decisions—proactive reroutes, self-healing actions, and chaos tests—all logged neatly. The system has spent the night not just surviving but improving itself, allowing the humans to focus on building new features instead of fighting fires.
Conclusion: The Unseen Heroes, Always On Guard
From accepting the inevitability of failure to mastering stateless agility, untangling stateful complexity, deploying silent sentinel tools, and nurturing a culture of resilience—we’ve journeyed through the intricate world of automated system recovery.
But the real “Unseen Heroes” aren’t just hidden in lines of code or humming servers. They are the engineers who anticipate failures before they happen, the processes designed to adapt and recover, and the mindset that treats resilience not as a milestone but as an ongoing craft. Together, they ensure that our digital infrastructure stays available, consistent, and trustworthy—even when chaos strikes.
In the end, automated recovery is more than technology; it’s a quiet pact between human ingenuity and machine intelligence, always working behind the scenes to keep the digital world turning.
May your systems hum like clockwork, your failures whisper instead of roar, and your recovery be as effortless as the dawn breaking after a storm.