Have you ever started a new Python project and, within a week, everything already feels messy?
Your config.py file is slowly becoming a dumping ground. There are commented lines everywhere, database URLs hardcoded directly in the file, and if ENV == “prod” conditions scattered across the codebase. At first, it feels manageable. But very quickly, it becomes difficult to understand what is actually being used and what is not.
And somewhere in the back of your mind, there is always that small fear: What if I accidentally expose a production password or push the wrong configuration?
This kind of setup might work for a small script. But as the project grows, it becomes hard to maintain and almost impossible to scale properly. And yes, this still happens even in the modern world of AI-assisted coding, irrespective of which model we use.
Over time, I realized that the cleanest way to handle configuration is not through complex .ini files or deeply nested dictionaries. I prefer using Python class inheritance along with environment variables. In some projects, I also pair this with Pydantic for validation when things get more complex.
Here’s how I structure my configuration systems to keep them type-safe, secure, and, most importantly, easy to read.
The Foundation
First, we need to talk about secrets. Hardcoding a Telegram token inside your code is basically inviting trouble. The simplest solution is to move sensitive values into a .env file and load them from environment variables.
One important rule. Never commit your .env file to Git. Instead, keep a .env.example file with empty placeholders so your team knows what variables are required.
This class holds the defaults. Everything common lives here. No duplication.
When I need environment-specific behavior, I simply inherit and override only what is required.
For example, in end-to-end testing, I might want notifications enabled but routed differently.
class E2EConfig(Config): """Overrides for E2E testing""" TESTING = True TELEGRAM_SEND_NOTIFICATIONS = True E2E_NOTIFICATION_BOT = 'Admin Bot'
For unit or integration testing, I definitely do not want real Telegram messages going out. I also prefer an in-memory database for speed.
class TestConfig(Config): """Overrides for local unit tests""" TESTING = True SQLALCHEMY_DATABASE_URI = 'sqlite:///:memory:' # Use in-memory DB for speed TELEGRAM_SEND_NOTIFICATIONS = False WTF_CSRF_ENABLED = False
Notice something important here. I am not copying the entire base class. I am only overriding what changes. That alone reduces many future mistakes.
To avoid magic strings floating around in the logic layer, I sometimes pair this with enums.
from enum import Enum
class LogType(Enum): STREAM_PUBLISH = 'STREAM_PUBLISH' NOTIFICATION = 'NOTIFICATION'
Now my IDE knows the valid options. Refactoring becomes safer. Typos become less likely.
Loading the configuration is also simple. In Flask, I usually use a factory pattern and switch based on one environment variable.
import os from flask import Flask from config import Config, E2EConfig, TestConfig
def create_app(): app = Flask(__name__)
# Select config based on APP_ENV environment variable env = os.environ.get("APP_ENV", "production").lower()
# Load the selected class app.config.from_object(configs.get(env, Config))
return app
That is it. One variable controls everything. No scattered if-else checks across the codebase.
Over time, this pattern has saved me from configuration-related surprises. All settings live in one place. Inheritance avoids copy-paste errors. Tests do not accidentally spam users because TELEGRAM_SEND_NOTIFICATIONS is explicitly set to False in TestConfig.
And if tomorrow I need a StagingConfig or DevConfig, I just add a small class that extends Config. Three or four lines, and I am done.
Configuration management may not be glamorous, but it decides how stable your application feels in the long run. A clean structure here reduces mental load everywhere else.
In Ansible, the “Flat Namespace” problem is a frequent stumbling block for engineers managing multi-tier environments. It occurs because Ansible merges variables from various sources (global, group, and host) into a single pool for the current execution context.
If you aren’t careful, trying to use a variable meant for “Group A” while executing tasks on “Group B” will cause the play to crash because that variable simply doesn’t exist in Group B’s scope.
The Scenario: The “Mixed Fleet” Crash
Imagine you are managing a fleet of Web Servers (running on port 8080) and Database Servers (running on port 5432). You want a single “Security” play to validate that the application port is open in the firewall.
The Failing Code:
- name: Apply Security Rules hosts: web:database vars: # This is the "Flat Namespace" trap! # Ansible tries to resolve BOTH variables for every host. app_port_map: web_servers: "{{ web_custom_port }}" db_servers: "{{ db_instance_port }}"
tasks: - name: Validate port is defined ansible.builtin.assert: that: app_port_map[group_names[0]] is defined
This code fails when Ansible runs this for a web_server, it looks at app_port_map. To build that dictionary, it must resolve db_instance_port. But since the host is a web server, the database group variables aren’t loaded. Result: fatal: 'db_instance_port' is undefined.
Solution 1: The “Lazy” Logic
By using Jinja2 whitespace control and conditional logic, we prevent Ansible from ever looking at the missing variable. It only evaluates the branch that matches the host’s group.
- name: Apply Security Rules hosts: app_servers:storage_servers vars: # Use whitespace-controlled Jinja to isolate variable calls target_port: >- {%- if 'app_servers' in group_names -%} {{ app_service_port }} {%- elif 'storage_servers' in group_names -%} {{ storage_backend_port }} {%- else -%} 22 {%- endif -%}
tasks: - name: Ensure port is allowed in firewall community.general.ufw: rule: allow port: "{{ target_port | int }}"
The advantage of this approach is that it’s very explicit, prevents “Undefined Variable” errors entirely, and allows for easy defaults. However, it can become verbose/messy if you have a large number of different groups.
Solution 2: The hostvars Lookup
If you don’t want a giant if/else block, you can use hostvars to dynamically grab a value, but you must provide a default to keep the namespace “safe.”
This approach is very compact and follows a naming convention (e.g., groupname_port). But its harder to debug and relies on strict variable naming across your entire inventory.
Solution 3: Group Variable Normalization
The most “architecturally sound” way to solve the flat namespace problem is to use the same variable name across different group_vars files.
# Playbook - main.yml --- - name: Unified Firewall Play hosts: all tasks: - name: Open service port community.general.ufw: port: "{{ service_port }}" # No logic needed! rule: allow
This is the cleanest playbook code; truly “Ansible-native” way of handling polymorphism but it requires refactoring your existing variable names and can be confusing if you need to see both ports at once (e.g., in a Load Balancer config).
The “Flat Namespace” problem is really just a symptom of Ansible’s strength: it’s trying to make sure everything you’ve defined is valid. I recently solved this problem in a multi-play playbook, which I wrote for Digital Ocean infrastructure provisioning and configuration using the Lazy Logic approach, and I found this to be the best way to bridge the gap between “Group A” and “Group B” without forcing a massive inventory refactor. While I have generalized the example code, I actually faced this problem in a play that set up the host-level firewall based on dynamic inventory.
In today’s cloud-centric world, where virtual machines and containers seem to materialize on demand, it’s easy to overlook the physical infrastructure that makes it all possible. For the new generation of engineers, a deeper understanding of what it takes to build and manage the massive fleets of physical machines that host our virtualized environments is becoming increasingly critical. While the cloud offers abstraction and on-demand scaling, the reality is that millions of physical servers, networked and orchestrated with precision, form the bedrock of these seemingly limitless resources. One of the key technologies that enables the rapid provisioning of these servers is the Preboot Execution Environment (PXE).
Unattended Setups and Network Booting: An Introduction to PXE
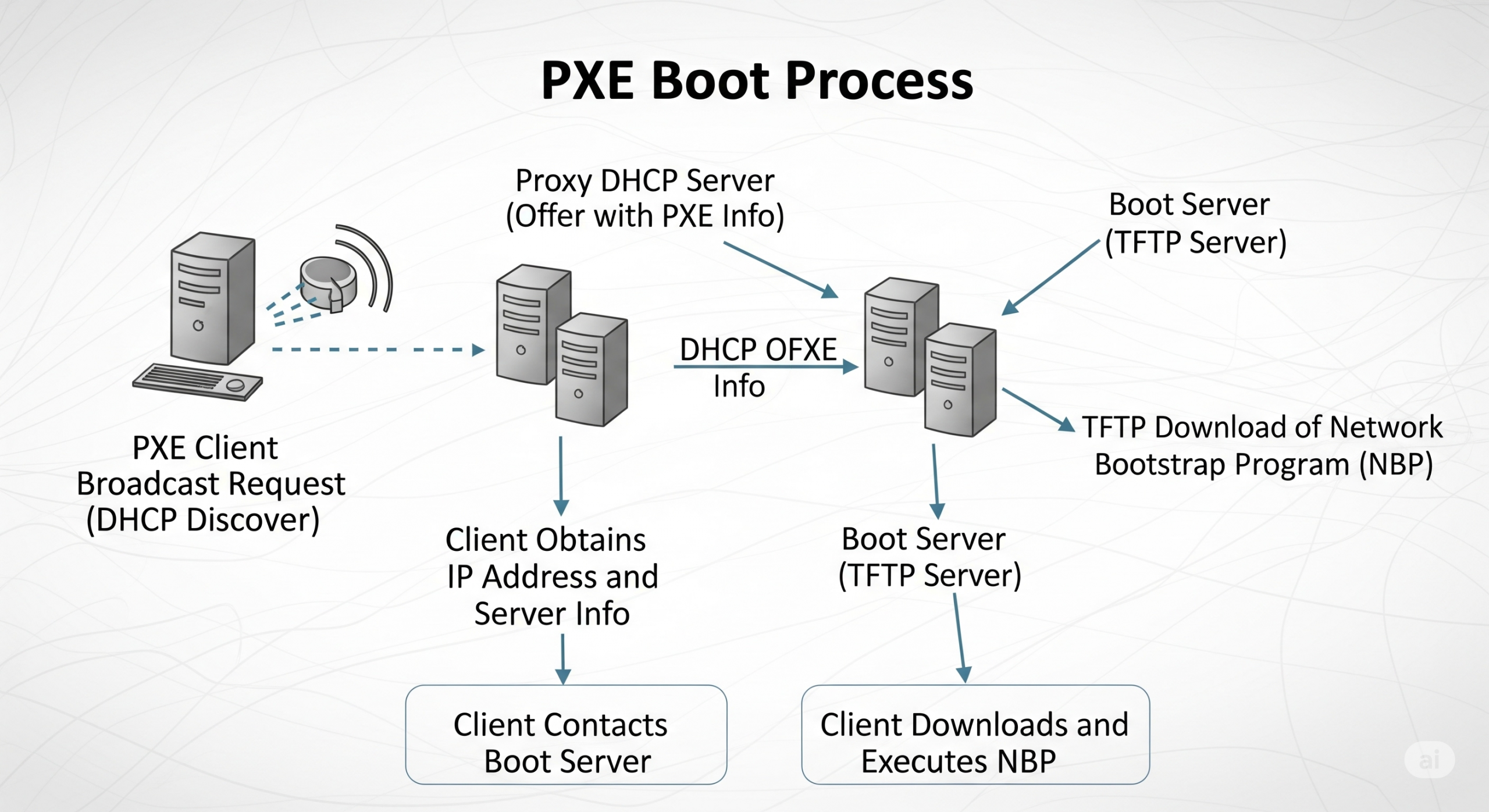
PXE provides a standardized environment for computers to boot directly from a network interface, independent of any local storage devices or operating systems. This capability is fundamental for achieving unattended installations on a massive scale. The PXE boot process is a series of network interactions that allow a bare-metal machine to discover boot servers, download an initial program into its memory, and begin the installation or recovery process.
The Technical Details of How PXE Works
The PXE boot process is a series of choreographed steps involving several key components and network protocols:
Discovery
When a PXE-enabled computer is powered on, its firmware broadcasts a special DHCPDISCOVER packet that is extended with PXE-specific options. This packet is sent to port 67/UDP, the standard DHCP server port.
Proxy DHCP
A PXE redirection service (or Proxy DHCP) is a key component. If a Proxy DHCP receives an extended DHCPDISCOVER, it responds with an extended DHCPOFFER packet, which is broadcast to port 68/UDP. This offer contains critical information, including:
A PXE Discovery Control field to determine if the client should use Multicasting, Broadcasting, or Unicasting to contact boot servers.
A list of IP addresses for available PXE Boot Servers.
A PXE Boot Menu with options for different boot server types.
A PXE Boot Prompt (e.g., “Press F8 for boot menu”) and a timeout.
The Proxy DHCP service can run on the same host as a standard DHCP service but on a different port (4011/UDP) to avoid conflicts.
Boot Server Interaction
The PXE client, now aware of its boot server options, chooses a boot server and sends an extended DHCPREQUEST packet, typically to port 4011/UDP or broadcasting to 67/UDP. This request specifies the desired PXE Boot Server Type.
Acknowledgement
The PXE Boot Server, if configured for the client’s requested boot type, responds with an extended DHCPACK. This packet is crucial as it contains the complete file path for the Network Bootstrap Program (NBP) to be downloaded via TFTP (Trivial File Transfer Protocol).
Execution
The client downloads the NBP into its RAM using TFTP. Once downloaded and verified, the PXE firmware executes the NBP. The functions of the NBP are not defined by the PXE specification, allowing it to perform various tasks, from presenting a boot menu to initiating a fully automated operating system installation.
The Role of PXE in Modern Hyperscale Infrastructure
While PXE has existed for years, its importance in the era of hyperscale cloud computing is greater than ever. In environments where millions of physical machines need to be deployed and managed, PXE is the first and most critical step in an automated provisioning pipeline. It enables:
Rapid Provisioning: Automating the initial boot process allows cloud providers to provision thousands of new servers simultaneously, dramatically reducing deployment time.
Standardized Deployment: PXE ensures a consistent starting point for every machine, allowing for standardized operating system images and configurations to be applied fleet-wide.
Remote Management and Recovery: PXE provides a reliable way to boot machines into diagnostic or recovery environments without requiring physical access, which is essential for managing geographically distributed data centers.
Connecting the Virtual to the Physica
For new engineers, understanding the role of technologies like PXE bridges the gap between the virtual world of cloud computing and the bare-metal reality of the hardware that supports it. This knowledge is not just historical; it is a foundation for:
Designing Resilient Systems: Understanding the underlying infrastructure informs the design of more scalable and fault-tolerant cloud-native applications.
Effective Troubleshooting: When issues arise in a virtualized environment, knowing the physical layer can be crucial for diagnosing and resolving problems.
Building Infrastructure as Code: The principles of automating physical infrastructure deployment are directly applicable to the modern practice of Infrastructure as Code (IaC).
By appreciating the intricacies of building and managing the physical infrastructure, engineers can build more robust, efficient, and truly cloud-native solutions, ensuring they have a complete picture of the technology stack from the bare metal to the application layer.
For decades, cron has been the trusty workhorse for scheduling tasks on Linux systems. Need to run a backup script daily? cron was your go-to. But as modern systems evolve and demand more robust, flexible, and integrated solutions, systemd timers have emerged as a superior alternative. Let’s roll up our sleeves and dive into the strategic advantages of systemd timers, then walk through their design and implementation..
Why Ditch Cron? The Strategic Imperative
While cron is simple and widely understood, it comes with several inherent limitations that can become problematic in complex or production environments:
Limited Visibility and Logging:cron offers basic logging (often just mail notifications) and lacks a centralized way to check job status or output. Debugging failures can be a nightmare.
No Dependency Management:cron jobs are isolated. There’s no built-in way to ensure one task runs only after another has successfully completed, leading to potential race conditions or incomplete operations.
Missed Executions on Downtime: If a system is off during a scheduled cron run, that execution is simply missed. This is critical for tasks like backups or data synchronization.
Environment Inconsistencies:cron jobs run in a minimal environment, often leading to issues with PATH variables or other environmental dependencies that work fine when run manually.
No Event-Based Triggering:cron is purely time-based. It cannot react to system events like network availability, disk mounts, or the completion of other services.
Concurrency Issues:cron doesn’t inherently prevent multiple instances of the same job from running concurrently, which can lead to resource contention or data corruption.
systemd timers, on the other hand, address these limitations by leveraging the full power of the systemd init system. (We’ll dive deeper into the intricacies of the systemd init system itself in a future post!)
Integrated Logging with Journalctl: All output and status information from systemd timer-triggered services are meticulously logged in the systemd journal, making debugging and monitoring significantly easier (journalctl -u your-service.service).
Robust Dependency Management:systemd allows you to define intricate dependencies between services. A timer can trigger a service that requires another service to be active, ensuring proper execution order.
Persistent Timers (Missed Job Handling): With the Persistent=true option, systemd timers will execute a missed job immediately upon system boot, ensuring critical tasks are never truly skipped.
Consistent Execution Environment:systemd services run in a well-defined environment, reducing surprises due to differing PATH or other variables. You can explicitly set environment variables within the service unit.
Flexible Triggering Mechanisms: Beyond simple calendar-based schedules (like cron), systemd timers support monotonic timers (e.g., “5 minutes after boot”) and can be combined with other systemd unit types for event-driven automation.
Concurrency Control:systemd inherently manages service states, preventing multiple instances of the same service from running simultaneously unless explicitly configured to do so.
Granular Control: Timers offer second-resolution scheduling (with AccuracySec=1us), allowing for much more precise control than cron‘s minute-level resolution.
Randomized Delays:RandomizedDelaySec can be used to prevent “thundering herd” issues where many timers configured for the same time might all fire simultaneously, potentially overwhelming the system.
Designing Your Systemd Timers: A Two-Part Harmony
systemd timers operate in a symbiotic relationship with systemd service units. You typically create two files for each scheduled task:
A Service Unit (.service file): This defines what you want to run (e.g., a script, a command).
A Timer Unit (.timer file): This defines when you want the service to run.
Both files are usually placed in /etc/systemd/system/ for system-wide timers or ~/.config/systemd/user/ for user-specific timers.
The Service Unit (your-task.service)
This file is a standard systemd service unit. A basic example:
[Unit]
Description=My Daily Backup Service
Wants=network-online.target # Optional: Ensure network is up before running
[Service]
Type=oneshot # For scripts that run and exit
ExecStart=/usr/local/bin/backup-script.sh # The script to execute
User=youruser # Run as a specific user (optional, but good practice)
Group=yourgroup # Run as a specific group (optional)
# Environment="PATH=/usr/local/bin:/usr/bin:/bin" # Example: set a custom PATH
[Install]
WantedBy=multi-user.target # Not strictly necessary for timers, but good for direct invocation
Strategic Design Considerations for Service Units:
Type=oneshot: Ideal for scripts that perform a task and then exit.
ExecStart: Always use absolute paths for your scripts and commands to avoid environment-related issues.
User and Group: Run services with the least necessary privileges. This enhances security.
Dependencies (Wants, Requires, After, Before): Leverage systemd‘s powerful dependency management. For example, Wants=network-online.target ensures the network is active before the service starts.
Error Handling within Script: While systemd provides good logging, your scripts should still include robust error handling and exit with non-zero status codes on failure.
Output: Direct script output to stdout or stderr. journald will capture it automatically. Avoid sending emails directly from the script unless absolutely necessary; systemd‘s logging is usually sufficient.
The Timer Unit (your-task.timer)
This file defines the schedule for your service.
[Unit]
Description=Timer for My Daily Backup Service
Requires=your-task.service # Ensure the service unit is loaded
After=your-task.service # Start the timer after the service is defined
[Timer]
OnCalendar=daily # Run every day at midnight (default for 'daily')
# OnCalendar=*-*-* 03:00:00 # Run every day at 3 AM
# OnCalendar=Mon..Fri 18:00:00 # Run weekdays at 6 PM
# OnBootSec=5min # Run 5 minutes after boot
Persistent=true # If the system is off, run immediately on next boot
RandomizedDelaySec=300 # Add up to 5 minutes of random delay to prevent stampedes
[Install]
WantedBy=timers.target # Essential for the timer to be enabled at boot
Strategic Design Considerations for Timer Units:
OnCalendar: This is your primary scheduling mechanism. systemd offers a highly flexible calendar syntax (refer to man systemd.time for full details). Use systemd-analyze calendar "your-schedule" to test your expressions.
OnBootSec: Useful for tasks that need to run a certain duration after the system starts, regardless of the calendar date.
Persistent=true:Crucial for reliability! This ensures your task runs even if the system was powered off during its scheduled execution time. The task will execute once systemd comes back online.
RandomizedDelaySec: A best practice for production systems, especially if you have many timers. This spreads out the execution of jobs that might otherwise all start at the exact same moment.
AccuracySec: Defaults to 1 minute. Set to 1us for second-level precision if needed (though 1s is usually sufficient).
Unit: This explicitly links the timer to its corresponding service unit.
WantedBy=timers.target: This ensures your timer is enabled and started automatically when the system boots.
Implementation and Management
Create the files: Place your .service and .timer files in /etc/systemd/system/.
Reload systemd daemon: After creating or modifying unit files: sudo systemctl daemon-reload
Enable the timer: This creates a symlink so the timer starts at boot: sudo systemctl enable your-task.timer
Start the timer: This activates the timer for the current session: sudo systemctl start your-task.timer
Check status:sudo systemctl status your-task.timer; sudo systemctl status your-task.service
View logs:journalctl -u your-task.service
Manually trigger the service (for testing):sudo systemctl start your-task.service
Conclusion
While cron served its purpose admirably for many years, systemd timers offer a modern, robust, and integrated solution for scheduling tasks on Linux systems. By embracing systemd timers, you gain superior logging, dependency management, missed-job handling, and greater flexibility, leading to more reliable and maintainable automation. It’s a strategic upgrade that pays dividends in system stability and ease of troubleshooting. Make the switch and experience the power of a truly systemd-native approach to scheduled tasks.
While trying to figure out an error, I found the following line in one of the crontab files and I could not stop myself from smiling.
PATH=$PATH:/opt/mysoftware/bin
And that single line perfectly encapsulated the misconception I want to address today: No, a crontab is NOT a shell script!
It’s a common trap many of us fall into, especially when we’re first dabbling with scheduling tasks on Linux/Unix systems. We’re used to the shell environment, where scripts are king, and we naturally assume crontab operates under the same rules. But as that PATH line subtly hints, there’s a fundamental difference.
The Illusion of Simplicity: What a Crontab Looks Like
At first glance, a crontab file seems like it could be a script. You define commands, specify execution times, and often see environmental variables being set, just like in a shell script. Here’s a typical entry:
0 2 * * * /usr/bin/some_daily_backup.sh
This tells cron to run /usr/bin/some_daily_backup.sh every day at 2:00 AM. Looks like a command in a script, right? But the key difference lies in how that command is executed.
Why Crontab is NOT a Shell Script: The Environment Gap
The critical distinction is this: When cron executes a job, it does so in a minimal, non-interactive shell environment. This environment is significantly different from your interactive login shell (like Bash, Zsh, or even a typical non-login shell script execution).
Let me break down the implications, and why that PATH line I discovered was so telling:
Limited PATH
This is perhaps the most frequent culprit for “my cron job isn’t working!” errors. Your interactive shell has a PATH variable populated with directories where executables are commonly found (e.g., /usr/local/bin, /usr/bin, /bin). The default PATH for cron jobs is often severely restricted, sometimes just to /usr/bin:/bin.
This means if your script or command relies on an executable located outside of cron’s default PATH (like /opt/mysoftware/bin/mycommand), it simply won’t be found, and the job will fail. That’s why the PATH=$PATH:/opt/mysoftware/bin line was necessary – it explicitly tells cron where to look for executables for that specific job.
Minimal Environment Variables
Beyond PATH, most other environment variables you rely on in your interactive shell (like HOME, LANG, TERM, or custom variables you’ve set in your .bashrc or .profile) are often not present or have very basic values in the cron environment.
Consider a script that needs to know your HOME directory to find configuration files. If your cron job simply calls this script without explicitly setting HOME, the script might fail because it can’t locate its resources.
No Interactive Features
Cron jobs run non-interactively. This means:
No terminal attached.
No user input (prompts, read commands, etc.).
No fancy terminal features (like colors or cursor manipulation).
No aliases or shell functions defined in your dotfiles.
If your script assumes any of these, it will likely behave unexpectedly or fail when run by cron.
Specific Shell Invocation
While you can specify the shell to be used for executing cron commands (often done with SHELL=/bin/bash at the top of the crontab file), even then, that shell is invoked in a non-login, non-interactive mode. This means it won’t necessarily read your personal shell configuration files (.bashrc, .profile, .zshrc, etc.) unless explicitly sourced.
The “Lot of Information” Cron Needs: Practical Examples
So, if crontab isn’t a shell script, what “information” does it need to operate effectively in this minimalist shell? It needs explicit instructions for everything you take for granted in your interactive session.
Let’s look at some common “incorrect” entries, what people expected, and how they should be corrected.
Example 1: Missing the PATH
The incorrect entry would look something like below:
0 * * * * my_custom_command
The user expected here was, “I want my_custom_command to run every hour. It works perfectly when I type it in my terminal.”
The my_custom_command is likely located in a directory that’s part of the user’s interactive PATH (e.g., /usr/local/bin/my_custom_command or /opt/mysoftware/bin/my_custom_command). However, cron’s default PATH is usually minimal (/usr/bin:/bin), so it cannot find my_custom_command. The error usually manifests as a “command not found” message mailed to the cron user or present in the syslog.
The fix here would be to always use the full, absolute path to your executables as shown in the below sample entry:
0 * * * * /usr/local/bin/my_custom_command
Or, if multiple commands from that path are used, you can set the PATH at the top of the crontab:
PATH=/usr/local/bin:/usr/bin:/bin # Add other directories as needed
0 * * * * my_custom_command
Example 2: Relying on Aliases or Shell Functions
The incorrect entry would look like below:
@reboot myalias_cleanup
The user assumed that, “I have an alias myalias_cleanup='rm -rf /tmp/my_cache/*' defined in my .bashrc. I want this cleanup to run every time the system reboots.”
But the aliases and shell functions are defined within your interactive shell’s configuration files (.bashrc, .zshrc, etc.). Cron does not source these files by default when executing jobs. Therefore, myalias_cleanup is undefined in the cron environment, leading to a “command not found” error.
The correct thing would be to replace aliases or shell functions with the actual commands or create a dedicated script.
# If myalias_cleanup was 'rm -rf /tmp/my_cache/*'
@reboot /bin/rm -rf /tmp/my_cache/*
Or, if it’s a complex set of commands, put them into a standalone script and call that script:
# In /usr/local/bin/my_cleanup_script.sh:
#!/bin/bash
/bin/rm -rf /tmp/my_cache/*
# ... more commands
# In crontab:
@reboot /usr/local/bin/my_cleanup_script.sh
Example 3: Assuming User-Specific Environment Variables
The user expected here that, “I have export MY_API_KEY='xyz123' in my .profile. I want my script to run daily using this API key.”
This assumption is wrong as similar to aliases, cron does not load your .profile or other user-specific environment variable files. The MY_API_KEY variable will be undefined in the cron environment, causing the curl command to fail (e.g., “authentication failed” or an empty key parameter).
To fix this explicitly set required environment variables within the crontab entry or directly within the script. There are two possible options to do this:
Option A: In Crontab (good for a few variables specific to the cron job):
The user expected that, “My Django application lives in /home/user/my_app. When I’m in /home/user/my_app and run python manage.py cleanup_old_data, it works. I want this to run nightly.”
Again, this assumption is incorrect as when cron executes a job, the current working directory is typically the user’s home directory (~). So, cron would look for my_app/manage.py inside ~/my_app/manage.py, not /home/user/my_app/manage.py. This leads to “file not found” errors.
To fix this either use absolute paths for the script or explicitly change the directory before executing. Here are the examples using two possible options:
Note the && which ensures the python command only runs if the cd command is successful.
Example 5: Output Flooding and Debugging
To illustrate this case, look at the following incorrect example entry:
*/5 * * * * /usr/local/bin/my_chatty_script.sh
The user expected that, “I want my_chatty_script.sh to run every 5 minutes.”
This expectation is totally baseless as by default, cron mails any standard output (stdout) or standard error (stderr) from a job to the crontab owner. If my_chatty_script.sh produces a lot of output, it will quickly fill up the user’s mailbox, potentially causing disk space issues or overwhelming the mail server. While not a “failure” of the job itself, it’s a major operational oversight.
The correct way is to redirect output to a log file or /dev/null for production jobs.
Redirect to a log file (recommended for debugging and auditing):
The smile I had when I saw that PATH line in a crontab file was the smile of recognition – recognition of a fundamental operational truth. Crontab is a scheduler, a timekeeper, an orchestrator of tasks. It’s not a shell interpreter.
Understanding this distinction is crucial for debugging cron job failures and writing robust, reliable automated tasks. Always remember: when cron runs your command, it’s in a stark, bare-bones environment. You, the administrator (or developer), are responsible for providing all the context and information your command or script needs to execute successfully.
So next time you’re troubleshooting a cron job, don’t immediately blame the script. First, ask yourself: “Does this script have all the information and the right environment to run in the minimalist world of cron?” More often than not, the answer lies there.